
Learn how to cut Mean Time to Resolution (MTTR) by 30-70% using AIOps, agentic triage, and hyperautomation. A phased 18-month roadmap for IT and DevOps.

MTTR stands for Mean Time to Resolution, and it measures the average time elapsed from the moment an incident is detected to the moment it is fully resolved, and service is restored. It is one of the most critical KPIs in IT operations, DevOps, and customer support, directly tied to system availability, SLA compliance, and revenue protection.

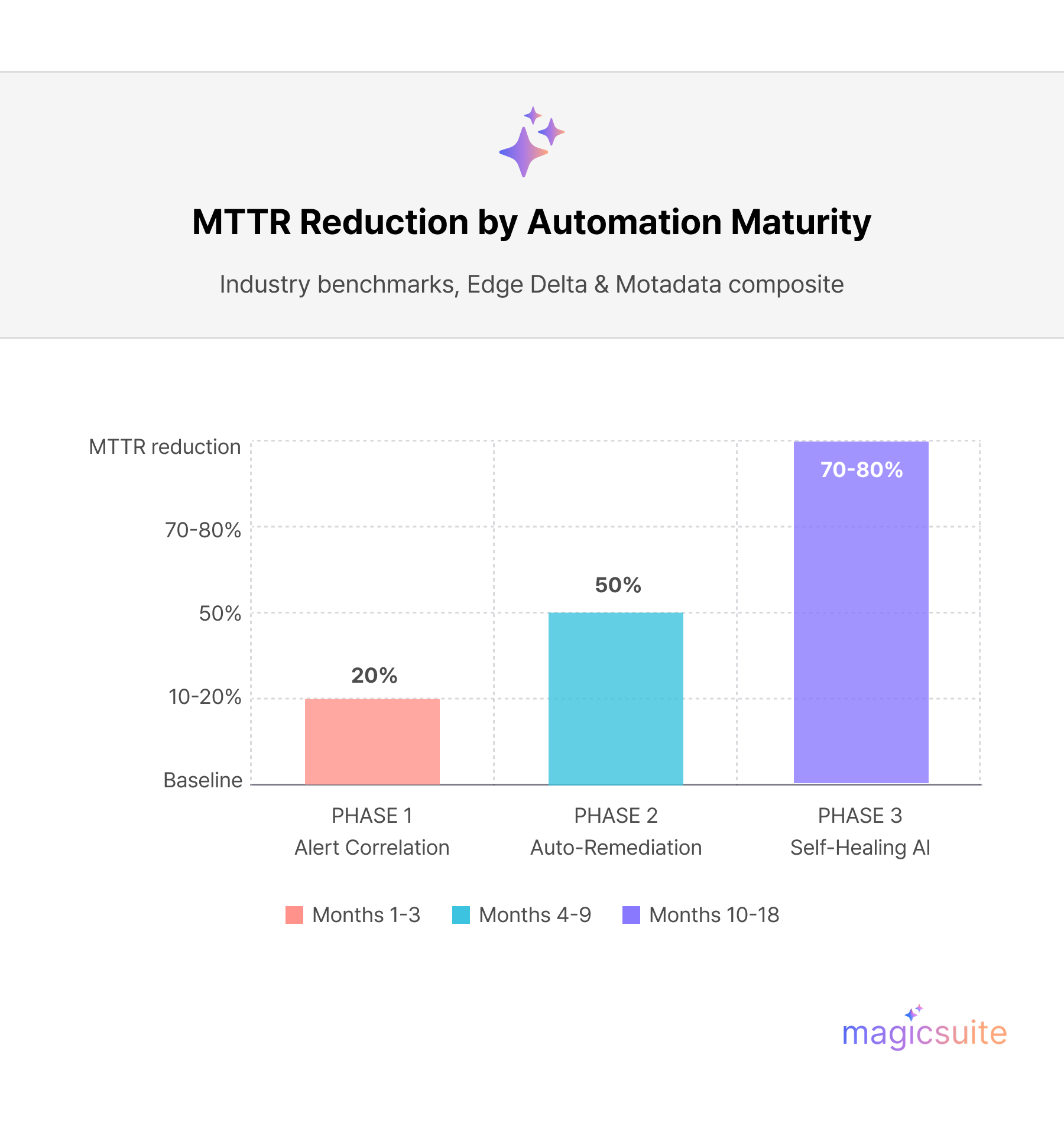
Industry benchmarks from Edge Delta and Motadata show that organizations deploying structured MTTR reduction programs achieve 30–70% improvements depending on their starting maturity level. The strategies below build on proactive systems, cultural shifts, and iterative automation to systematically compress each phase.
Our previous article talked about how to calculate MTTR. This time, we are going to dig into the strategies you can take to effectively lower your MTTR.
Deploy unified platforms like Dynatrace or LogicMonitor that ingest metrics, logs, traces, and events into a single pane. AI engines perform causal inference (e.g., correlating a CPU spike with a recent deployment via NLP-parsed logs), delivering root-cause hypotheses in under 90 seconds.
Enable agentic AI (e.g., Socrates or incident.io's AI SRE) for autonomous triage: it enriches alerts with context (IP reputation, user behavior), suppresses noise (60-90% alert reduction), and suggests remediations with confidence scores.
Build no-code/low-code pipelines in tools like Torq HyperSOC or Cutover: trigger on anomalies, execute playbooks (e.g., kill malicious processes, roll back configurations), and generate audit-ready reports in minutes. Layer in predictive maintenance like how ML models forecast failures from historical patterns, preempting 20-40% of incidents.
Use platforms with dynamic roles: AI assigns Incident Commander, auto-pulls SMEs via Slack/Teams, and runs parallel diagnostics. Implement "swarming" where AI triages into severity buckets, routing P1s to war rooms with live dashboards. Post-incident, AI auto-generates RCA templates, quantifying toil (e.g., manual hours saved) to prioritize automation.
4. Maturity Model Progression
Measure via dashboards tracking MTTD (<15min target), auto-resolution rate (>30%), and SLA adherence.
Several companies have achieved MTTR reductions of 40-70% using AI-driven incident management, as documented in recent case studies and benchmarks.

Meta deployed an internal AIOps platform across 300+ engineering teams, reducing MTTR for critical alerts by ~50%. AI focused on diagnosis compression, from ~95 minutes to ~18 minutes in similar setups, by automating telemetry analysis and pattern matching.
Organizations adopting Neurones' AI observability saw MTTR reductions of up to 70% and IT ops costs 15-35% lower. AI transformed raw telemetry into actionable insights, correlating hybrid/multi-cloud events to proactively fix 9% of apps that were previously fully observable.
Forrester studies highlight firms using full-stack observability (e.g., BigPanda integrations) hitting 70-90% MTTR reductions. One cohort achieved 85% less monitoring labor via AI automation, ensuring traceable decisions for compliance.
Reducing Mean Time to Resolution (MTTR) by 40-70% in 6-18 months involves a phased approach that combines AI tools, process improvements, and cultural shifts. Case studies, such as Meta’s 50-81% improvement and manufacturing companies’ 65% reductions, showcase the effectiveness of this approach.
Many organizations face challenges when rolling out MTTR automation due to poor planning, tool fragmentation, and resistance to change. These pitfalls can lead to stalled progress or even increased downtime despite investments.

Deploying automation without reducing alert noise can overwhelm teams with 150-300 alerts per week, many of which are false positives. Engineers end up spending 40-60% of their time filtering these alerts instead of diagnosing issues. To avoid this, prioritize AI-based alert correlation before scaling alert volume.
Using 10-15 siloed tools (e.g., Datadog, Splunk, PagerDuty) creates constant context-switching, requiring teams to work across multiple platforms. This leads to wasted time, around 30-45 minutes, on manual data aggregation. The solution is to centralize your observability stack early on to streamline workflows.
Attempting to automate flawed workflows can actually magnify inefficiencies. For example, scripting problematic runbooks can introduce more errors. Before automating, refine your processes through audits and post-mortems to ensure they’re at least 80% reliable.
Many teams lack the necessary observability expertise, with 48% of teams citing this as a barrier. This can lead to analysis paralysis when dealing with complex datasets. Without proper training or AI-assisted context, MTTR tends to rise. To combat this, mandate GameDays and create searchable wikis for continuous learning.
Relying on averages can mask important details, such as long-tail outages that may account for a disproportionate amount of downtime. Excluding non-repair delays can also skew your baselines. Instead, track granular metrics such as MTTD, diagnosis time, and the 90th percentile (P90) to get a more accurate picture.

Hanna is an industry trend analyst dedicated to tracking the latest advancements and shifts in the market. With a strong background in research and forecasting, she identifies key patterns and emerging opportunities that drive business growth. Hanna’s work helps organizations stay ahead of the curve by providing data-driven insights into evolving industry landscapes.