
RAG cuts hallucinations by up to 71% over fine-tuning alone in customer service AI deployments.

RAG (Retrieval-Augmented Generation) is an AI architecture that retrieves relevant documents from a verified knowledge base at inference time and constrains response generation to that retrieved content. Fine-tuning, by contrast, trains a Large Language Model (LLM) on a fixed dataset so the model internalizes domain-specific patterns, but generates answers from learned weights alone, without access to live documents at query time.
In customer service, this distinction determines whether the model can fabricate a policy it has never seen. RAG cannot answer with information that does not exist in its knowledge base. Fine-tuned models can, and do, fill gaps with plausible-sounding but incorrect content — the core mechanism behind LLM hallucinations.
Fine-tuning adapts a model's language patterns to a domain — tone, terminology, common phrasing — and performs well on queries that closely resemble its training data. The risk emerges at the edges: queries about updated policies, new products, or regulatory changes that postdate the training run.
As Cension AI's 2025 analysis confirms, fine-tuned models "can still hallucinate on anything new" because the knowledge encoded in weights does not update without a full retraining cycle. A model trained on last quarter's pricing table confidently answers questions about this quarter's pricing, generating numbers it has no access to. In regulated industries like telecom, insurance, or financial services, that confident fabrication creates compliance exposure, not just customer frustration.
Update cycles compound the problem. Fine-tuning typically requires weeks to months for data curation, training, evaluation, and deployment. Customer service knowledge, such as return windows, support tiers, and carrier policies, changes on shorter cycles. The gap between knowledge updates and model deployment is where the risk of hallucination is highest, and fine-tuning cannot close that gap structurally.
RAG's hallucination resistance is structural, not probabilistic. The model cannot generate an answer that lacks grounding in the retrieved documents because the retrieval step gates what information enters the generation context.
The Knowmax AI platform articulates the mechanism directly: a RAG customer service system answers only with information from its knowledge base, rather than fabricating responses based on pattern-matched weights. Every response includes a source citation, which serves as a real-time verification signal for both the system and the human reviewing the output.
This matters most in two high-frequency scenarios:
The 2023 Air Canada chatbot case, in which a fine-tuned model fabricated a bereavement discount policy for which Air Canada was held legally accountable, remains the clearest enterprise case study of the hallucination risk posed by fine-tuning at scale.
The headline finding from 2025–2026 research: hybrid RAG + fine-tuning architectures outperform either approach alone, and pure RAG outperforms pure fine-tuning on hallucination-critical tasks.
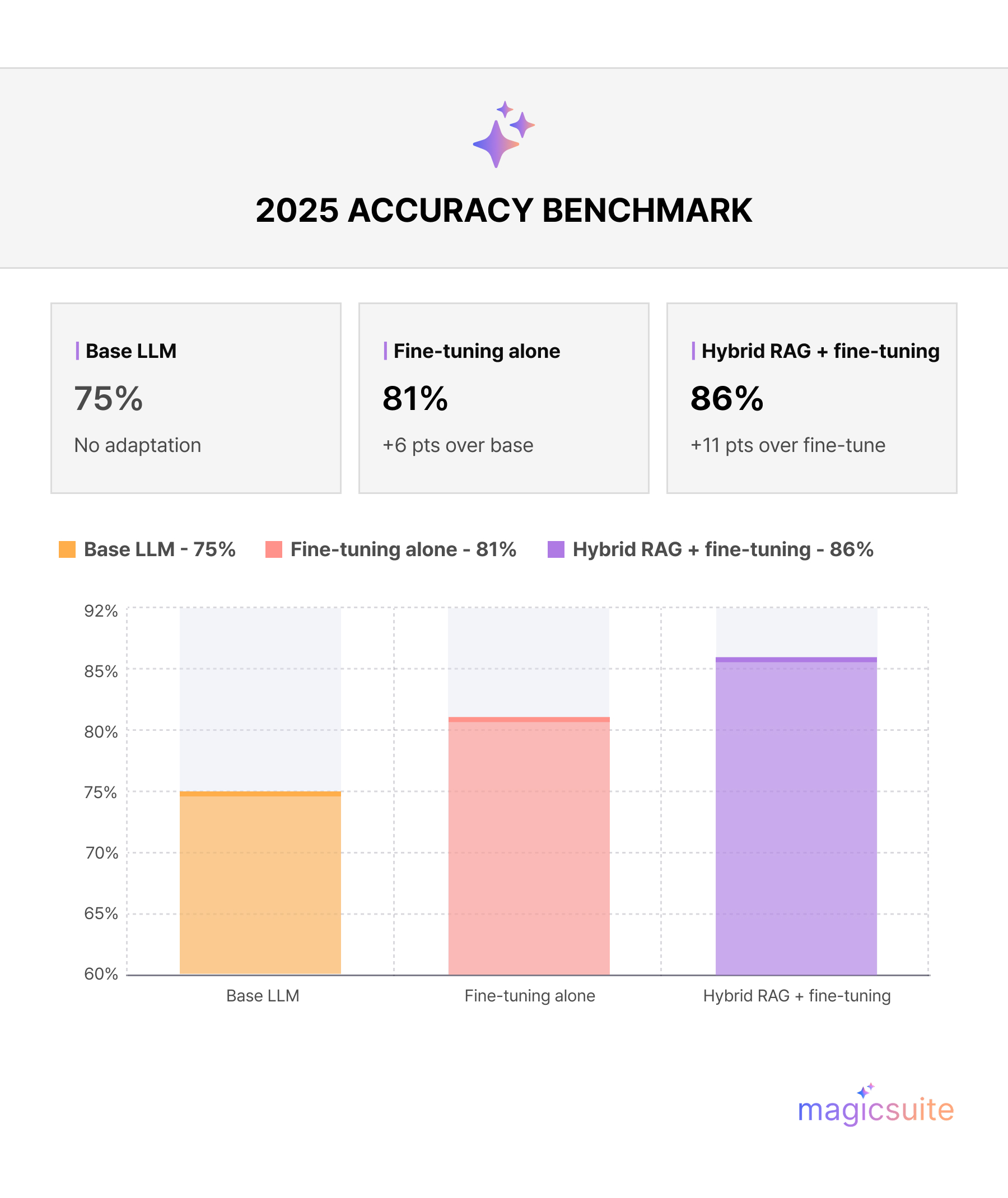
Fig.1. Hybrid RAG + fine-tuning reaches 86% accuracy in 2025 benchmarks, an 11-point gain over fine-tuning alone and a 14-point gain over a base LLM. The gap confirms that RAG's document grounding closes the accuracy ceiling that fine-tuning alone cannot reach.
A 2025 benchmark of specialized task performance (reported in arXiv, abs/2505.04847) found that hybrid fine-tune + RAG systems reached 86% accuracy versus 81% for fine-tuning alone and 75% for a base LLM — an 11-percentage-point improvement attributable to RAG's grounding mechanism. The benchmark confirms that fine-tuning improves over the base model, but RAG's document grounding closes an additional gap that fine-tuning alone cannot.
Vectara's FaithJudge leaderboard, updated in 2025, benchmarks RAG faithfulness across question-answering and summarization tasks and documents persistent yet improving hallucination rates across LLM providers when RAG context is supplied. The consistent finding: models hallucinate less when constrained by retrieved context than when generating from weights alone.
Scott Graffius, tracking enterprise AI deployments in 2026, reported that RAG reduces hallucinations by 40–71% in enterprise scenarios, a range that reflects the variance in retrieval quality, document freshness, and re-ranking implementation across deployments.

Fig. 2. RAG's structural constraint produces very low hallucination risk compared to fine-tuning's medium-high exposure. The risk gap widens every time a policy or product changes because fine-tuning lacks a mechanism to reflect the update until a full retraining cycle completes.
Fine-tuning carries medium-to-high hallucination risk, takes weeks to months to update, offers no citation support, and fits best for domain tone and vocabulary but requires full retraining whenever knowledge changes.
RAG delivers very low hallucination risk, updates in minutes, sources every response with citations, and is the strongest fit for dynamic policies, pricing, and compliance environments requiring real-time grounding.
Meanwhile, Hybrid RAG + fine-tuning achieves low hallucination risk, retains minute-level update speed through the RAG layer, includes citation support, and delivers best-in-class accuracy by combining fine-tuning for tone with RAG for factual grounding.
RAG deployments in contact centers produce measurable operational outcomes, not just improvements in benchmark accuracy. The data from 2025–2026 enterprise deployments reveals three consistent patterns.
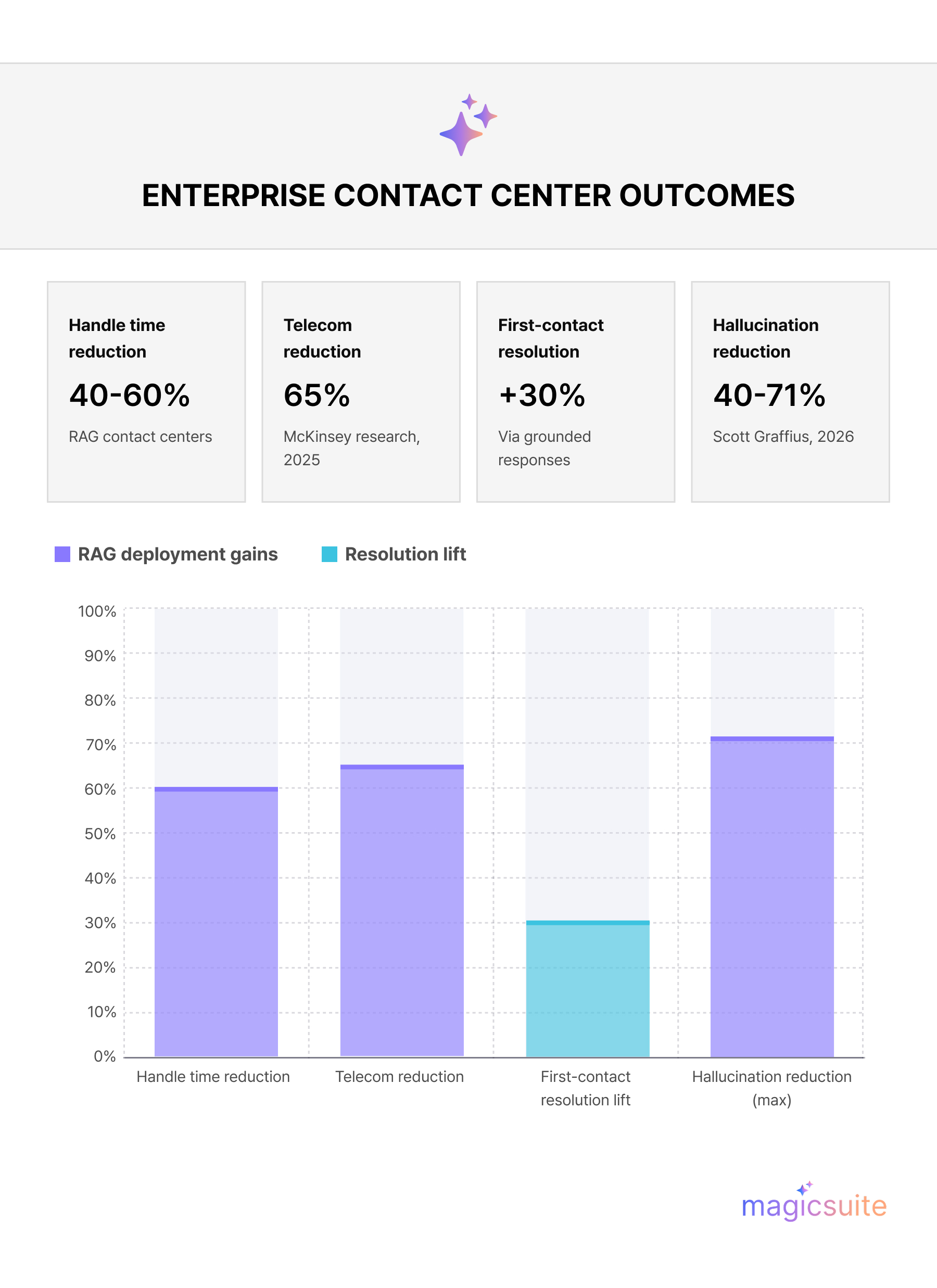
Fig. 3. RAG-powered contact centers report 40–60% handle time reductions and 30% higher first-contact resolution rates. McKinsey's 2025 telecom data puts the handle time cut at 65%.
GraphRAG is an evolution of standard RAG that structures the knowledge base as a graph of relationships between entities — policies, products, customer segments, regulatory categories — rather than a flat document store.
For customer service queries that require relational reasoning ("Does this policy exception apply to customers on the legacy plan who upgraded before March?"), GraphRAG retrieves not just the relevant document but the relevant connections between documents.
Enterprise deployments in 2026 report that GraphRAG improves accuracy for policy-linked relational queries — the class of queries in which standard RAG retrieves the right document but misses the relevant clause embedded in a related document. The hallucination mechanism here is subtle: the model retrieves the correct information but generates it from an incomplete context. GraphRAG addresses that by expanding retrieval to include relational context.
The implication for teams choosing an architecture is that, if the customer service knowledge base is relational—tiered pricing, conditional eligibility, cross-product dependencies—then GraphRAG's retrieval advantage over flat RAG becomes material.

Fig. 4. A knowledge base update in minutes; fine-tuned models require weeks to months for a full retraining cycle. In customer service environments, this speed gap is where hallucination risk accumulates — not at training time, but in the window between what changed and when the model catches up.
The binary framing of RAG versus fine-tuning misrepresents how high-performing customer service AI is actually built in 2025–2026. The benchmark data validates a hybrid approach as the architecture ceiling.
Fine-tuning contributes to tone calibration, domain-specific vocabulary, and response-style consistency — the model learns to sound like a support agent rather than a general-purpose AI. RAG provides factual grounding, real-time access to knowledge, and citation accountability. The 11-percentage-point accuracy advantage of hybrid systems over fine-tuning alone in 2025 benchmarks reflects the distinct contributions of each layer.
For teams starting from scratch, practitioners recommend deploying RAG first, because hallucination risk is the highest-severity failure mode in customer service AI. Layer fine-tuning once the retrieval system is stable and the knowledge base is well-maintained. Fine-tuning on top of a high-quality RAG architecture improves tone and response quality without reintroducing the hallucination risk that fine-tuning carries in isolation.

Luke is a technical market researcher with a deep passion for analyzing emerging technologies and their market impact. With a keen eye for data and trends, Luke provides valuable insights that help shape strategic decisions and product innovations. His expertise lies in evaluating industry developments and uncovering key opportunities in the ever-evolving tech landscape.