Why AI Hallucinates in Customer Support and How RAG Fixes It
March 20, 2026
4
mins
Learn what Retrieval-Augmented Generation (RAG) is and how it eliminates AI hallucinations to provide reliable, real-time customer support. See how RAG compares to fine-tuning.
Insight Summary
01. The Cost of Hallucination
Standard LLMs hallucinate at rates between 3% and 10%. For a team handling 10,000 monthly tickets, this translates to up to 1,000 misinformation incidents that erode customer trust and drive up operational costs.
02. Grounding Responses with RAG
Retrieval-Augmented Generation (RAG) grounds AI in a verified, company-specific knowledge base. By retrieving facts before generating text, it reduces hallucination rates to near zero compared to relying on static model memory.
03. Efficiency Over Expensive Fine-Tuning
Fine-tuning can cost between $50,000 and $200,000 per iteration. RAG leverages your existing infrastructure, offering a significantly more cost-effective path to maintaining an accurate, up-to-date AI system.
04. Real-Time Knowledge Updates
RAG systems update instantly. Editing a single document in your knowledge base immediately reflects in every AI response, eliminating the update lag that makes standard LLMs unreliable for fast-changing information.
05. Closing the Trust Gap
While 74% of leaders plan AI investment, 50% of customers still distrust bots. RAG’s ability to cite sources and show its reasoning is the essential mechanism needed to build lasting customer confidence.
The promise of Artificial Intelligence in customer support has long been shadowed by a singular, persistent fear: The Hallucination. Recent research shows that LLM hallucination rates vary widely, from 3% to 10%, depending on task complexity and model architecture. For a brand handling 10,000 tickets a month, that amounts to up to 1,000 potential misinformation incidents, eroding customer trust and increasing operational costs. This is where Retrieval-Augmented Generation (RAG) emerges as the industry-standard solution to bridge this critical "hallucination gap."
Fig. 1. AI Hallucination Rates where a small error can accumulate to become a crisis.
Why Standard LLMs Fall Short in Customer Support
To appreciate the transformative power of RAG, it is essential to understand the inherent limitations of standard Large Language Models (LLMs) like GPT-4 and Gemini.
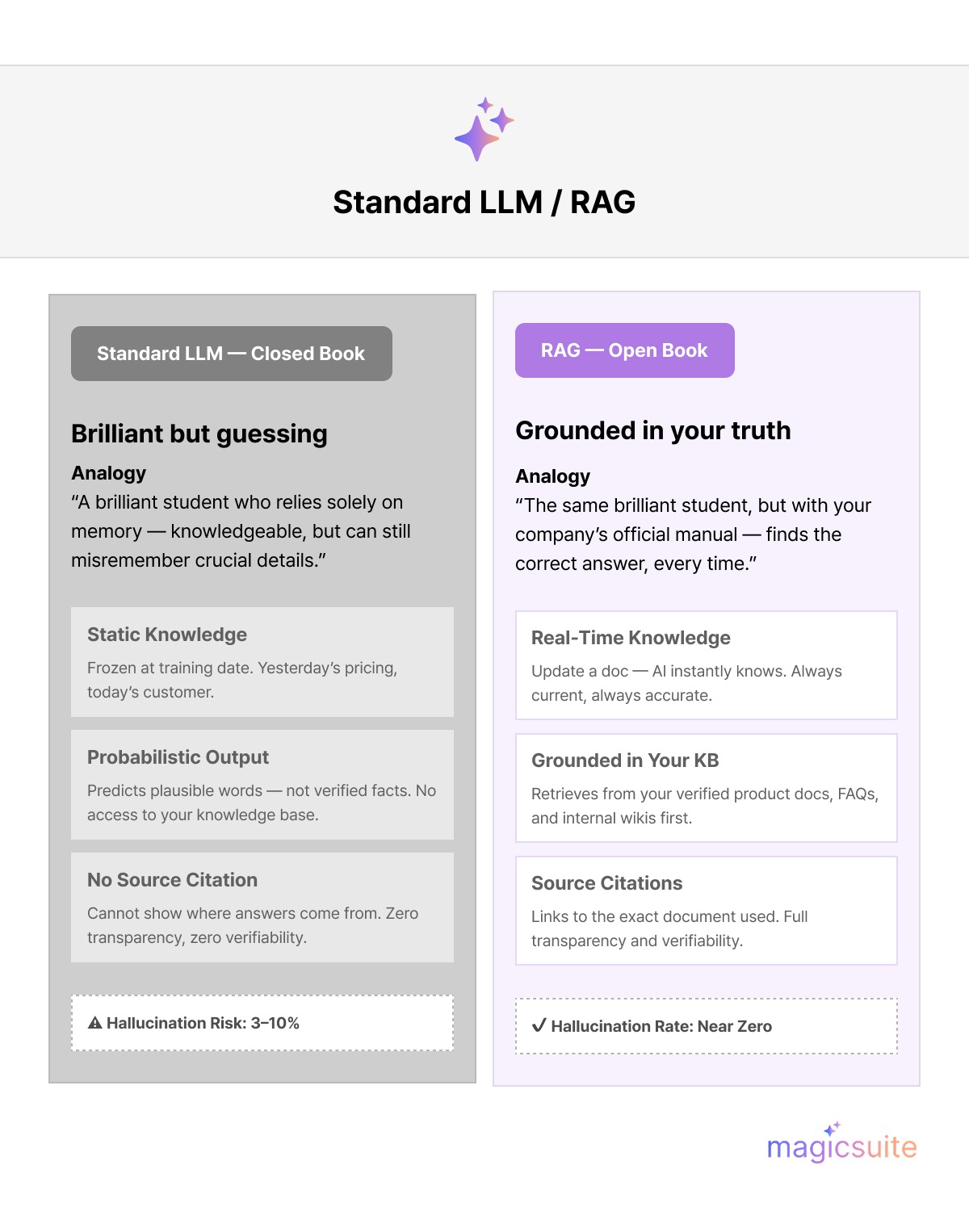
Fig. 2. Standard LLMs vs RAG in terms of Falling Short in Customer Support
Static Knowledge: An LLM’s knowledge is frozen at the time of its training. If your company updated its pricing last week, a standard LLM will continue to provide outdated information, leading to customer confusion and frustration.
Lack of Grounding: Traditional LLMs are probabilistic models that predict the next word in a sequence. They don't possess true understanding or access to your company's internal knowledge base. This can lead to the generation of plausible-sounding but incorrect information.
One of the key challenges in deploying LLMs is keeping their knowledge up to date with real-world changes. This is where RAG provides a significant advantage.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an advanced AI framework that enhances LLMs by grounding them in factual, up-to-date information. It works by retrieving relevant data from your specific knowledge base—such as product documentation, help center articles, and internal wikis- before the AI generates a response. Think of it as the difference between a closed-book and an open-book exam:
Standard AI (Closed-Book Exam): A brilliant student who relies solely on memory. They might be incredibly knowledgeable, but they can still misremember crucial details.
RAG AI (Open-Book Exam): The same brilliant student, but with your company's official manual. They don't guess; they find the correct information and provide a precise, reliable answer.
5 Data-Backed Benefits of RAG for Customer Support
Implementing RAG is not just a technological upgrade; it's a strategic investment in brand reputation, customer trust, and operational efficiency.
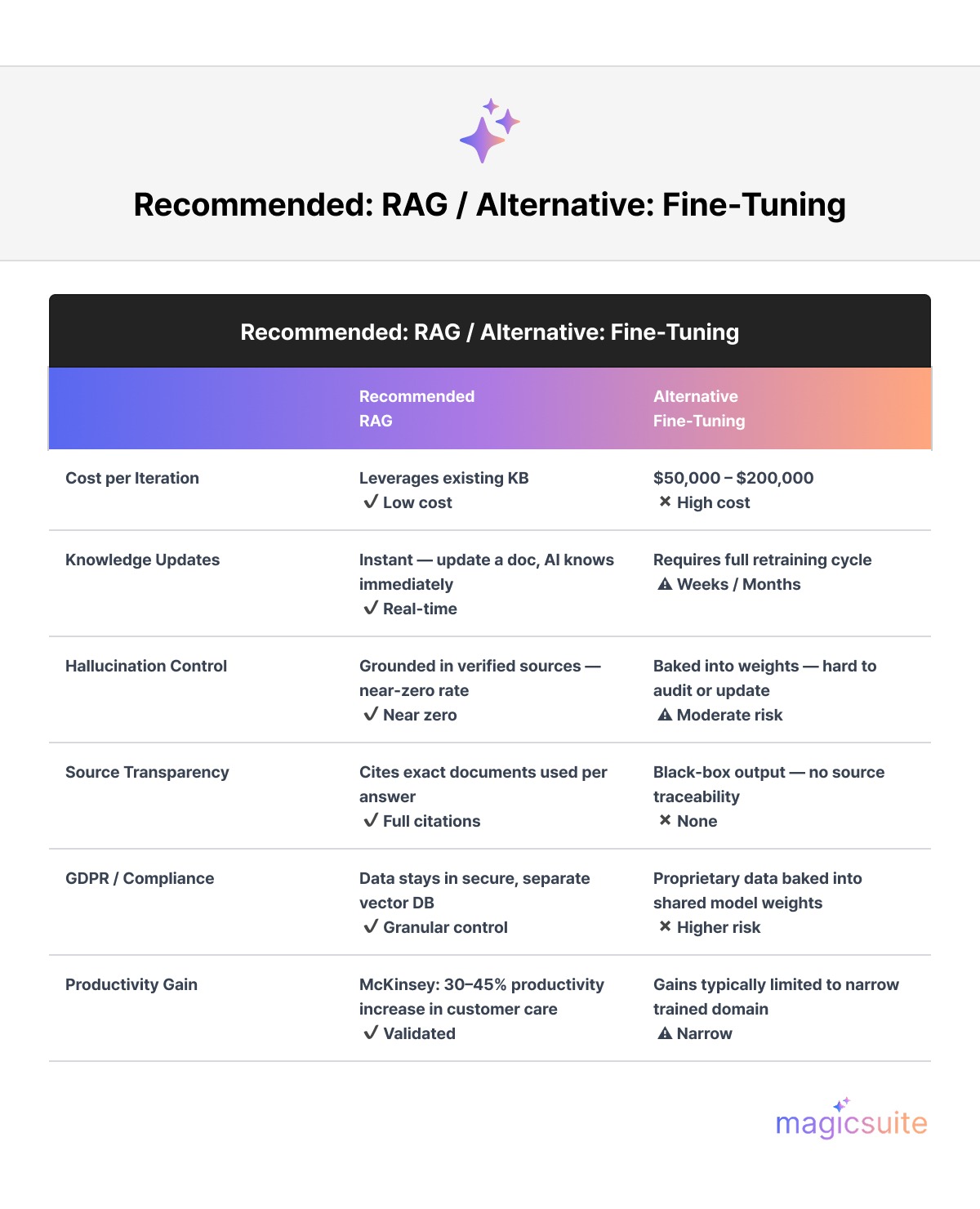
Near-Zero Hallucinations: By grounding responses in your verified knowledge base, RAG systems can reduce hallucination rates to near zero. If the information is not available, the AI is programmed to escalate to a human agent.
Real-Time Knowledge: With RAG, your AI is always up to date. Simply update a document in your knowledge base, and the AI will instantly have access to the new information.
Reduced Operational Costs: Fine-tuning an LLM can cost between $50,000 and $200,000 per iteration. RAG, on the other hand, leverages your existing knowledge base, making it a far more cost-effective solution. According to McKinsey & Company's 2023 report on the economic potential of generative AI, applying generative AI to customer care functions could increase productivity by 30–45%.
Enhanced Trust and Transparency: RAG models can cite their sources, providing users with links to the exact documents used to generate the response. This transparency builds trust and allows for easy verification.
Improved Security and Compliance: By keeping your proprietary data in a secure, separate vector database, RAG gives you granular control over data access, which is crucial for GDPR and other compliance requirements.
RAG vs. Fine-Tuning: A Comparative Analysis
Fig.3. RAG vs. Fine Tuning: Comparative Analysis
The Future is Grounded: Your Path to Reliable AI
A 2025 Intercom report revealed that while 74% of support leaders plan to invest in AI, 50% of customers remain hesitant to trust bots. RAG is the key to bridging this trust gap, replacing AI's unpredictable "creativity" with dependable "reliability."
Ready to transform your customer support with AI you can trust?
Visit MagicSuite.ai to discover how our RAG-powered platform can empower your team with accurate, real-time answers.
Luke is a technical market researcher with a deep passion for analyzing emerging technologies and their market impact. With a keen eye for data and trends, Luke provides valuable insights that help shape strategic decisions and product innovations. His expertise lies in evaluating industry developments and uncovering key opportunities in the ever-evolving tech landscape.