
Multimodal AI unifies voice, vision, and text in customer service — 80% of enterprise software by 2030.

Customer expectations have never been higher — or more complex. Customers today don't just want fast answers; they want contextual, intelligent, and seamless experiences across every channel they use. A customer service interaction might begin with a voice call, shift to a photo sent via chat, and conclude through a text summary delivered by email. Managing these modalities separately — as most organizations still do — creates friction, inconsistency, and missed resolution opportunities.
Multimodal AI changes that equation entirely. By combining voice, vision, and text processing within a single intelligent system, multimodal AI enables organizations to understand and respond to customers the way humans naturally communicate — across multiple channels, simultaneously, without context loss.
This article examines why multimodal AI represents the most consequential shift in AI customer service since the rise of conversational chatbots, how leading enterprises are deploying it today, what technical and operational challenges remain, and what business leaders must do to capitalize on this transformation before their competitors do.
To appreciate what multimodal AI delivers, it helps to understand what preceded it. Most organizations still operate customer service systems built around isolated modalities: a text-based AI chatbot for digital inquiries, a separate interactive voice response (IVR) system for phone support, and perhaps an image processing tool for specific document workflows. These systems work in silos. They do not share context, they cannot process inputs from multiple channels simultaneously, and they frequently force customers to repeat information when switching between touchpoints.
This fragmented architecture carries a measurable cost. According to Salesforce research, 73% of customers expect to start on one channel and finish on another without repeating themselves — yet only 33% of companies currently offer fully integrated omnichannel support. The gap between customer expectation and enterprise capability is not just a satisfaction problem. It is a revenue problem. Freshworks reports that 63% of customers say they would switch to a competitor offering a more fluid multi-channel experience.
Single-modality AI also struggles with nuance. A voice-only system cannot interpret a customer's photograph of a damaged product. A text-only AI chatbot cannot detect frustration in a caller's tone. Each isolated system sees only part of the picture, producing support experiences that feel incomplete — even when the underlying technology is sophisticated.
This is the structural gap that multimodal AI is engineered to close.
Multimodal AI refers to AI systems capable of processing, understanding, and generating outputs across multiple data types — specifically text, audio (voice), and visual inputs such as images and video — within a single integrated model or architecture. Unlike systems that bolt together separate tools for each modality, true multimodal AI shares context across all input types simultaneously, enabling richer and more accurate understanding of customer intent.
In practice, a multimodal customer service system can:
The underlying architecture typically involves large language models (LLMs) enhanced with vision encoders for image processing and speech processing modules for audio. Foundation models like Google's Gemini, OpenAI's GPT-4o, and Anthropic's Claude have accelerated this capability dramatically by embedding multimodal processing natively into a single model — rather than requiring separate specialized systems that introduce latency and reduce accuracy.
Generative AI adds another layer of capability. Rather than simply classifying or routing customer inputs, generative multimodal systems can synthesize information across modalities to produce coherent, contextually appropriate responses — explaining a warranty policy while simultaneously analyzing a photograph of a defective product, for example, or generating a personalized resolution based on both the content of a voice call and a customer's prior chat history.
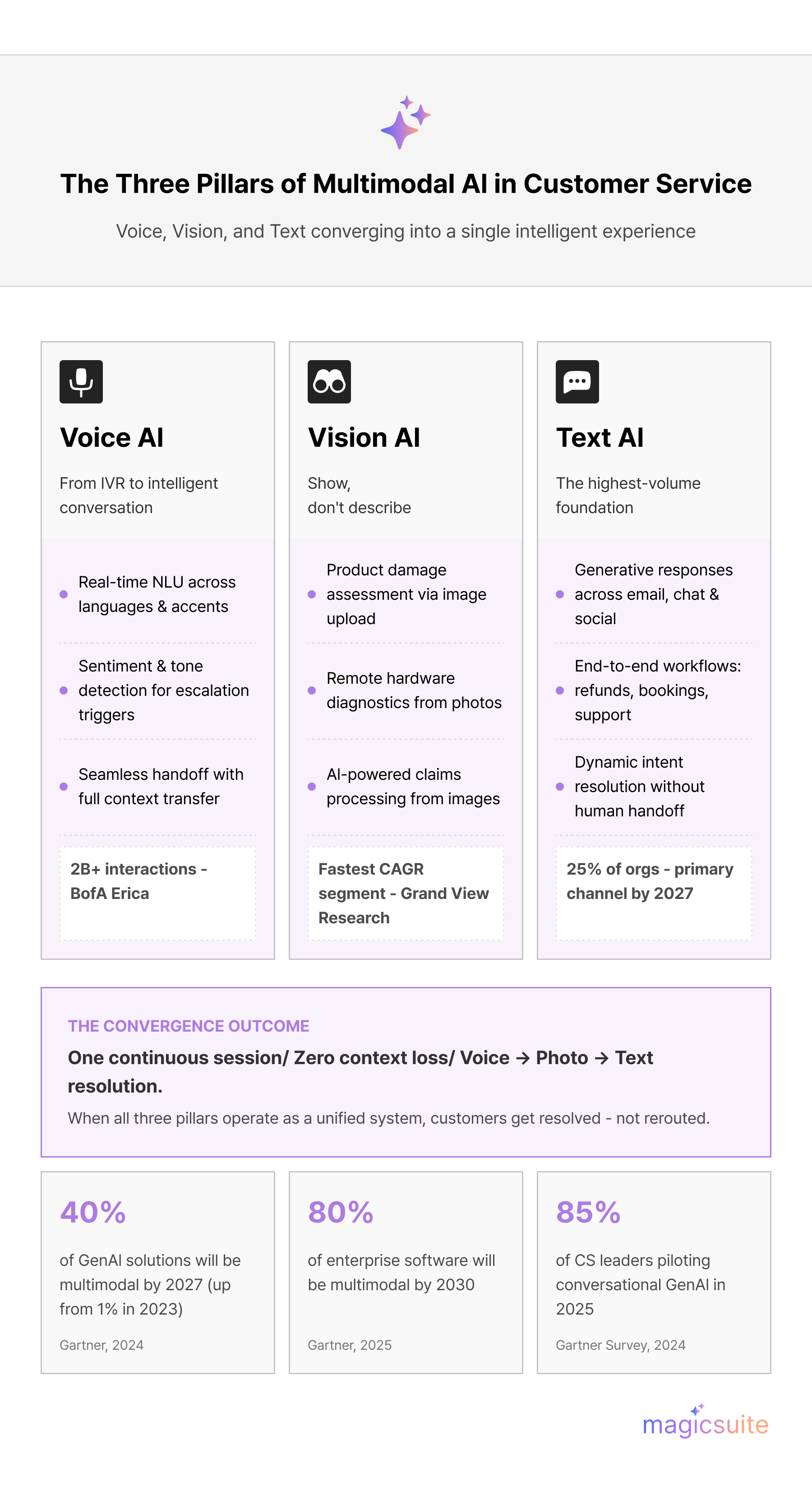
Voice AI in customer service has evolved from rigid, menu-driven IVR systems to sophisticated conversational AI capable of natural, open-ended dialogue. Modern voice systems process not just what a customer says, but how they say it — detecting urgency, frustration, or confusion through acoustic signals that purely text-based systems cannot access.
The business case for voice AI investment is compelling. Gartner predicts that conversational AI will reduce contact center labor costs by $80 billion by 2026, reflecting the scale of automation now achievable across high-volume phone channels. Bank of America's virtual assistant, Erica, illustrates what mature voice AI can accomplish at enterprise scale: customers have completed over 2 billion interactions with Erica since launch, with more than 98% of users receiving answers within 44 seconds on average.
Key capabilities now standard in enterprise Voice AI deployments include:
Visual AI is perhaps the least-discussed but most practically transformative pillar of multimodal customer experience transformation. When a customer can show rather than describe a problem — photographing a damaged shipment, uploading a screenshot of an error message, or sharing a video of a malfunctioning device — resolution speed and accuracy improve dramatically.
In retail and e-commerce, vision AI enables product identification, damage assessment, and return authorization through image analysis rather than manual agent review. In telecommunications, visual AI allows customers to share photographs of hardware issues for remote diagnostic support. In insurance, AI-powered image analysis accelerates claims processing by interpreting photographs submitted by policyholders.
According to Grand View Research, the computer vision segment is anticipated to grow at the fastest CAGR within the broader AI customer service market through 2033 — a projection that reflects the expanding range of business problems this capability can solve.
Text remains the highest-volume modality in enterprise customer service, handling email, live chat, social media messaging, and knowledge base interactions. Generative AI has fundamentally elevated what text-based systems can accomplish — moving from keyword-triggered response templates to contextually intelligent, dynamically generated answers that adapt to each individual customer query.
Modern AI chatbot platforms powered by generative AI now handle end-to-end service workflows: processing refunds, rescheduling bookings, troubleshooting technical issues, and escalating complex cases — not merely deflecting inquiries to human agents. According to Gartner, 25% of organizations will use chatbots as their primary customer service channel by 2027, a projection that underscores how central text AI has become to enterprise service strategy.
The convergence of all three — voice, vision, and text — within a unified multimodal architecture is what elevates the customer experience from merely automated to genuinely intelligent.
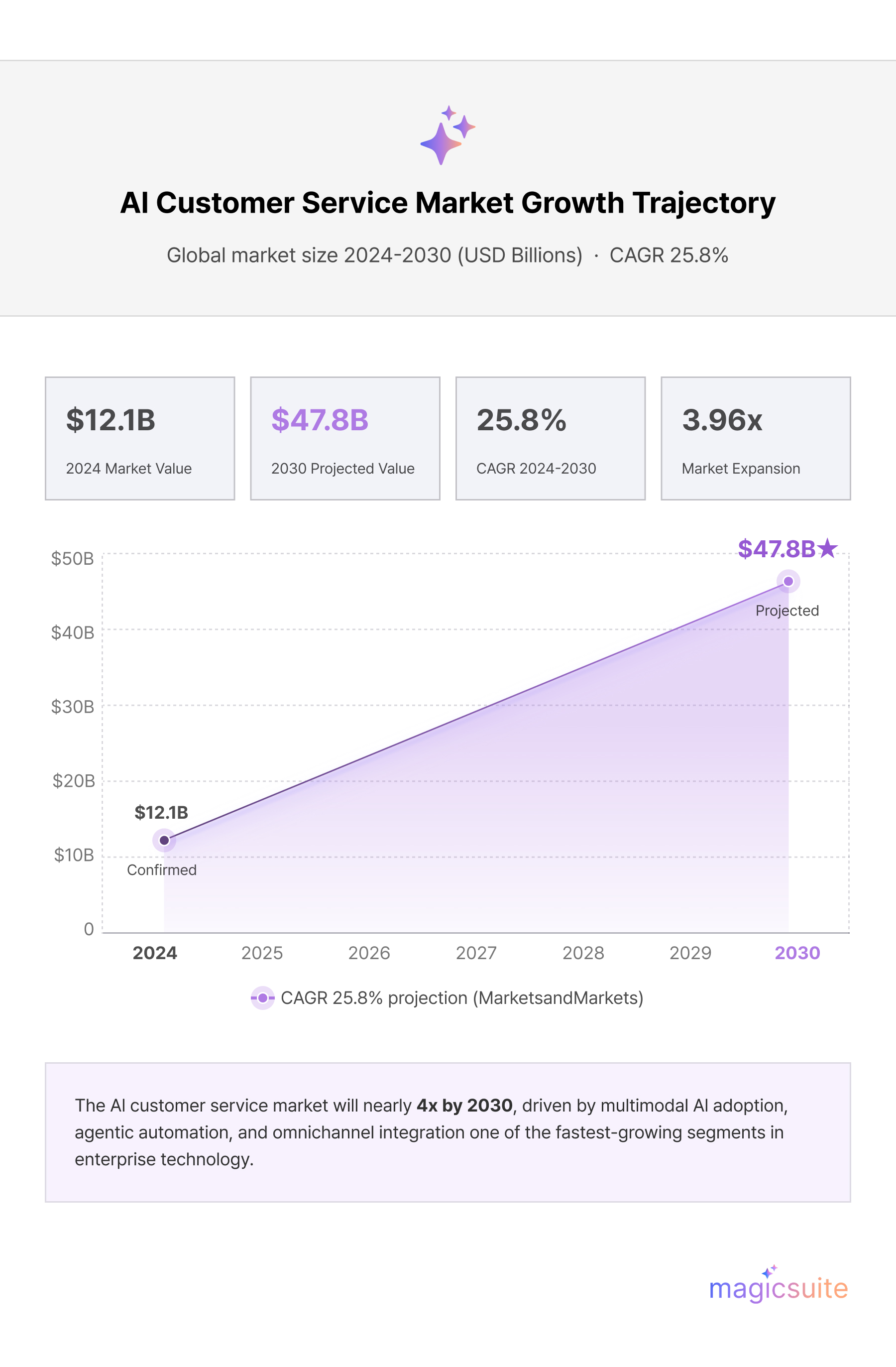
The adoption data paints a picture of a market in rapid transition. According to MarketsandMarkets, the AI customer service market was valued at $12.06 billion in 2024 and is projected to reach $47.82 billion by 2030, at a CAGR of 25.8%. Polaris Market Research offers an even bolder projection, suggesting the market could reach $117.87 billion by 2034.
Several data points define the current adoption landscape:
North America currently leads adoption, accounting for over 35% of market revenue in 2024, though the Asia-Pacific region is expanding fastest, driven by mobile-first economies where conversational AI for e-commerce on messaging platforms has already produced measurable gains in handling high-volume inquiries.
The enterprise AI investment rationale is increasingly clear. Companies report an average return of $3.50 for every $1 invested in AI customer service, with top-performing organizations achieving up to 8x ROI. AI automation is expected to save businesses $79 billion annually by 2025, a figure that reflects the breadth of operational workflows now amenable to AI-driven resolution.
What distinguishes leading organizations from laggards is not tool selection — it is deployment discipline. Gartner notes that only 20% of AI projects are fully meeting expectations, and 42% of companies abandoned most AI initiatives in 2025 — up dramatically from 17% the prior year. The implication is unambiguous: speed of adoption matters less than quality of implementation.
Klarna's AI-powered customer service deployment has become one of the most widely cited benchmarks in enterprise AI. In February 2024, the company launched an OpenAI-powered assistant that handled the equivalent work of 700 full-time agents in its first month of global operation — completing 2.3 million conversations, reducing repeat inquiries by 25%, and cutting average resolution time from 11 minutes to under 2 minutes. The financial impact was equally significant: reduced support costs per transaction by 40%, with an AI agent handling 66% of all customer requests.
What made Klarna's deployment effective was not just automation volume — it was the deliberate design of resolution workflows. The assistant was configured to complete real service tasks: processing refunds, managing returns, resolving disputes, and handling invoice issues. It operated multilingually, supported customers across dozens of languages, and provided a seamless escalation path to human agents when needed.
Notably, by mid-2025, Klarna acknowledged that the aggressive pace of automation had created quality gaps for complex interactions, and the company began re-hiring human agents — a candid admission from its own CEO that the strategy had gone too far. This development does not undermine the initial data, which remained accurate. Rather, it reinforces a central argument of this article: multimodal AI deployment must be paired with deliberate human escalation architecture. The goal is not maximum automation — it is optimal resolution.
Bank of America's virtual assistant Erica represents a mature model of conversational AI deployed at institutional scale. Customers have engaged in over 2 billion interactions with Erica since its launch, with approximately 2 million daily engagements and a 98%+ rate of answers delivered within 44 seconds. Erica integrates voice and text modalities, provides proactive financial alerts, and intelligently routes complex cases to human advisors — combining automation efficiency with the relational depth that banking customers require.
In February 2025, Google enhanced its Customer Engagement Suite with Gemini-powered conversational agents designed for advanced omnichannel customer support and real-time quality evaluation. The platform enables organizations to deploy multimodal, multilingual virtual agents capable of processing voice, text, and visual inputs across multiple service channels — representing Google's vision for the future of AI-augmented enterprise customer experience.
Deploying multimodal AI effectively is not primarily a model selection challenge — it is an architectural and integration challenge. True omnichannel customer support powered by multimodal AI requires a unified data layer that preserves customer context across every touchpoint: voice, chat, email, social media, and in-person interactions.
The critical infrastructure requirements for enterprise multimodal AI include:
McKinsey research confirms that more than 50% of consumers use three to five different channels during the customer journey. Industry benchmarks from companies implementing intelligent omnichannel strategies further document 43% improvements in resolution time and 67% increases in first contact resolution. The infrastructure investment required to support these outcomes is substantial — but so is the competitive advantage it creates.
The business case for multimodal AI in customer service is strong, but the path to effective deployment is not without obstacles. Enterprise leaders who approach implementation without a clear-eyed view of the risks will join the growing cohort of organizations that have abandoned AI initiatives after failing to meet expectations.
The primary challenges include:
Data privacy and regulatory compliance. Multimodal systems that process voice recordings, photographs, and biometric signals face a significantly more complex regulatory environment than text-only AI. GDPR in Europe, CCPA in California, and an expanding patchwork of sector-specific regulations impose strict requirements on data retention, consent, and explainability that multimodal architectures must be designed to satisfy from the outset — not retrofitted after deployment.
Integration complexity. Most large enterprises operate customer service infrastructure built across multiple platforms, acquired through years of technology investment and vendor relationships. Integrating multimodal AI with legacy CRM systems, existing contact center platforms, and specialized vertical applications requires significant technical effort and organizational alignment. Microsoft's Dynamics 365, Salesforce Service Cloud, and Zendesk have each developed AI-native omnichannel capabilities, but connecting them to proprietary backend systems remains a non-trivial engineering challenge.
Model accuracy and hallucination risk. Generative AI models can produce confident but incorrect responses — a risk that is amplified in customer service contexts where inaccurate information about policies, pricing, or procedures has direct business and reputational consequences. Enterprises must implement robust evaluation frameworks, human-in-the-loop review mechanisms, and clearly defined escalation triggers to manage accuracy risk at scale.
Bias and fairness in multimodal systems. Voice AI systems can exhibit performance disparities across different accents, dialects, and languages. Visual AI systems may underperform for certain demographic groups depending on training data composition. Enterprises deploying multimodal AI at scale must invest in ongoing bias auditing and model evaluation across diverse customer populations.
Change management and workforce transition. Deploying multimodal AI inevitably reshapes agent roles. Organizations that fail to invest in workforce reskilling and clear communication about AI's role — augmenting rather than simply replacing human agents — risk both operational disruption and talent attrition in customer service functions.
Organizations that will lead in multimodal AI customer service over the next three to five years share a common strategic posture: they treat AI deployment as an operating model transformation, not a technology procurement decision.
Practical recommendations for enterprise decision-makers:
The trajectory of multimodal AI in customer service points toward a future where the distinction between channels effectively disappears. A customer will initiate contact however is most convenient — voice, text, image, or video — and the AI will understand, respond, and resolve across all of them within a single, continuous experience.
Gartner's prediction that 80% of enterprise software will be multimodal by 2030 is not a forecast about technology alone — it is a forecast about competitive expectation. By the end of this decade, multimodal capability will not be a differentiator; it will be a baseline requirement. The competitive advantage accrues now, to organizations building the infrastructure, governance, and operational expertise that make effective multimodal deployment possible.
Emerging developments that will accelerate this transition include:
The organizations that treat multimodal AI as a strategic infrastructure investment today will be the ones defining what exceptional customer experience looks like tomorrow.

Hanna is an industry trend analyst dedicated to tracking the latest advancements and shifts in the market. With a strong background in research and forecasting, she identifies key patterns and emerging opportunities that drive business growth. Hanna’s work helps organizations stay ahead of the curve by providing data-driven insights into evolving industry landscapes.