
A/B test AI chatbot responses to cut drop-off rates and improve task completion with real evidence.

A/B testing AI chatbot responses is the practice of comparing two or more response variations empirically to determine which performs better against a defined goal. Also called chatbot split testing, it converts vague intuition about "what sounds better" into measurable evidence and it is the most reliable method for optimizing AI chatbot responses at scale. This guide covers the complete process: from test design and user segmentation to statistical validation and continuous chatbot response optimization.
A/B testing for chatbots, also called chatbot split testing, involves randomly assigning users to different versions of an AI chatbot response and tracking which version achieves the target metric more effectively.
The control group receives the original response (Version A), while one or more treatment groups receive variations (Version B, C, and so on). Unlike traditional software testing, which checks whether code executes correctly, A/B testing AI chatbot responses evaluates whether a response works for humans. A technically flawless AI chatbot response can still fail if its tone, length, or phrasing causes users to disengage. A/B testing surfaces those gaps with evidence rather than assumptions.
AI-powered chatbots built on large language models (LLMs) produce different outputs for the same input across sessions. Standard QA catches syntax errors; it does not catch a response that is technically correct but conversationally off-putting. This unpredictability is why empirical testing is essential rather than optional for LLM-powered systems.
Research confirms that 73% of consumers who have a poor experience with a virtual assistant will not return to use it. A single underperforming AI chatbot response flow, scaled across thousands of daily conversations, compounds that damage rapidly, which is why conversational AI testing at the response level is a business-critical practice, not a nice-to-have.
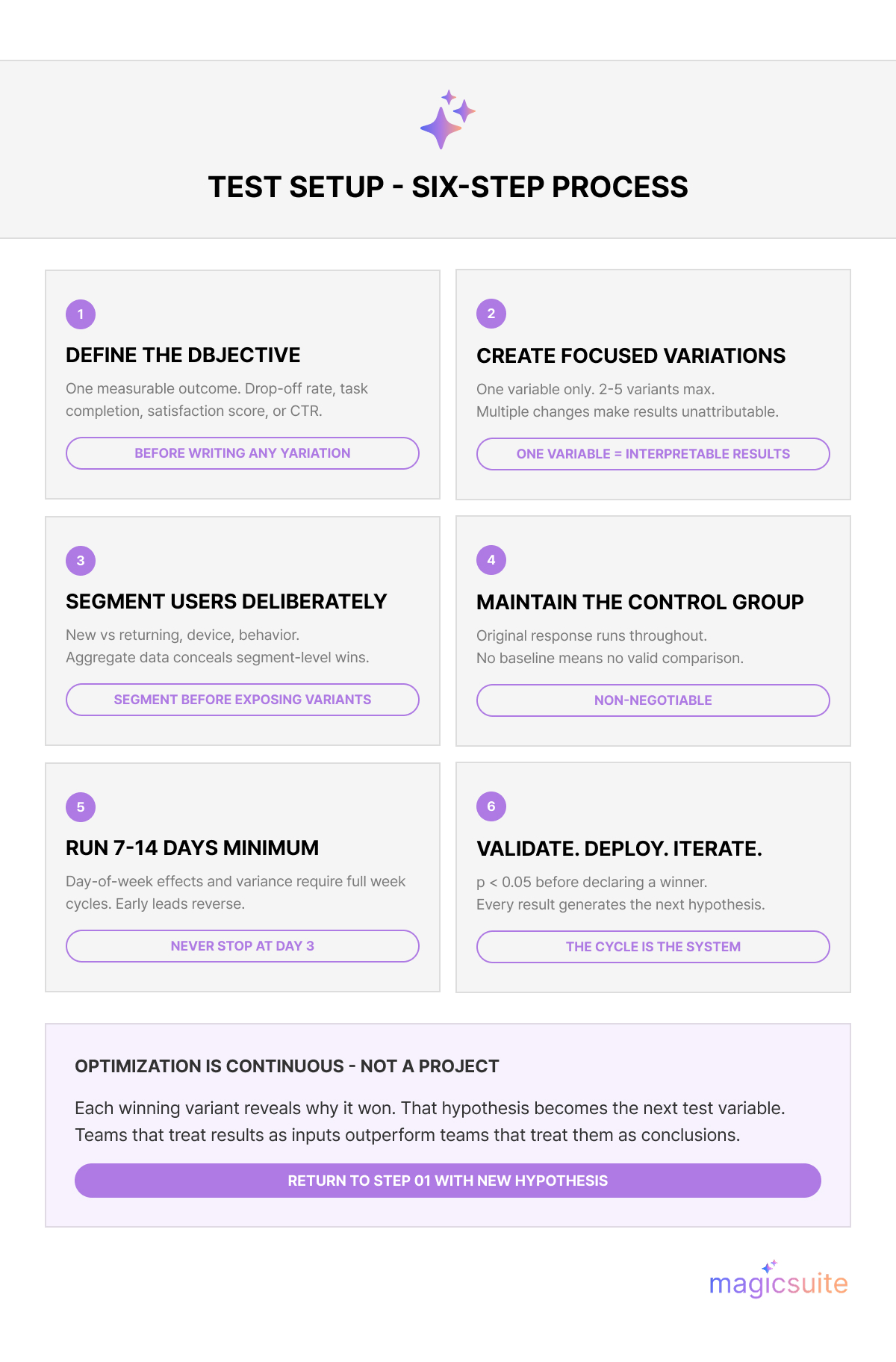
Fig 01. Test Setup Flow
Vague goals produce uninterpretable results. Before writing a single variation, define exactly what you want to improve. Objectives with direct business impact include reducing mid-conversation drop-off rates, increasing the percentage of users who complete a support task without agent escalation, improving post-conversation satisfaction scores, or raising click-through rates on product recommendation responses. Confirming the objective upfront prevents the common mistake of collecting data first and hunting for meaning afterward.
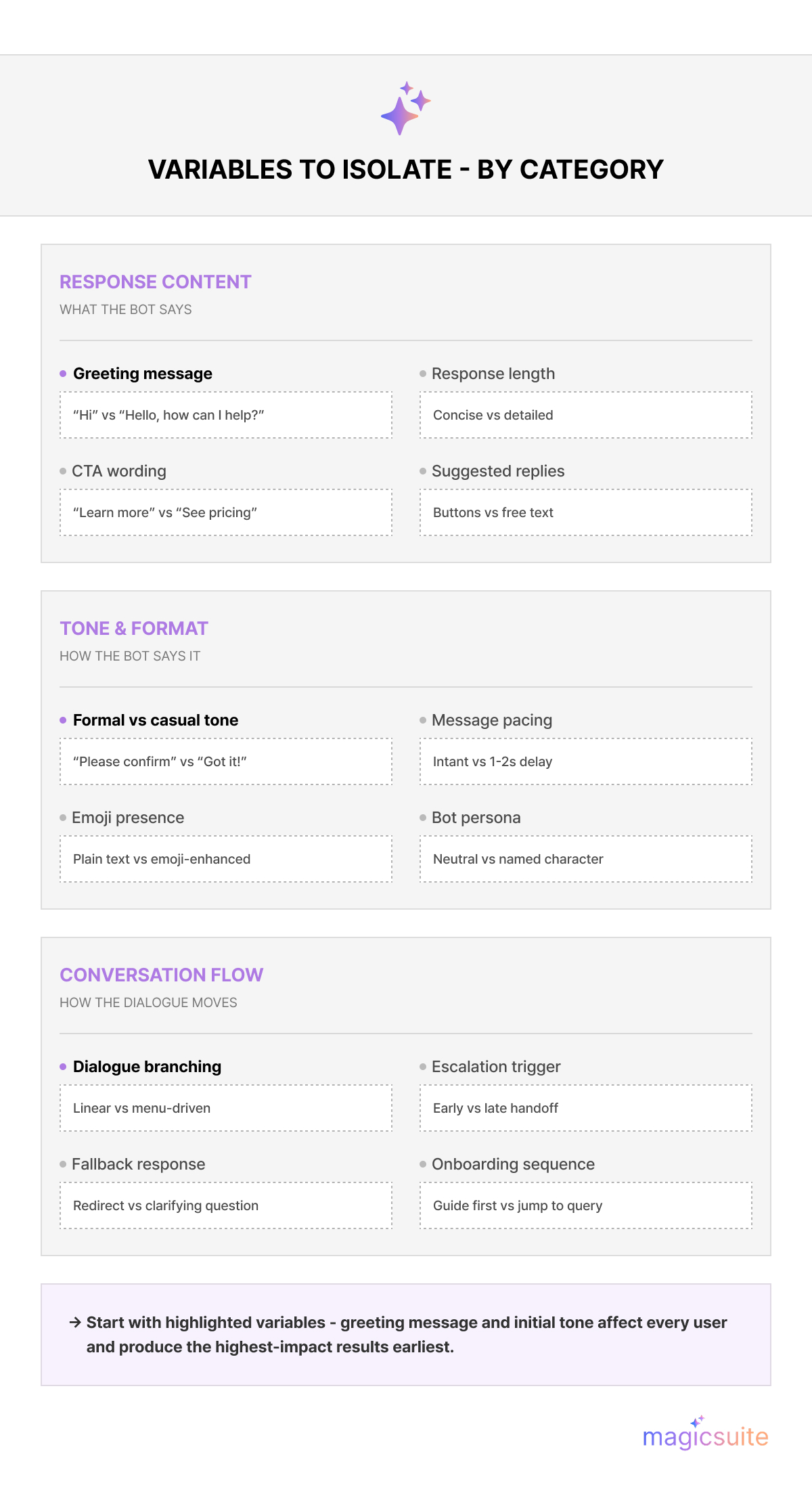
Fig 02. Variables to Isolate
Testing one variable at a time is the core discipline that makes A/B testing valid. When multiple elements change simultaneously, there is no way to attribute performance differences to a specific cause. Variables worth isolating include AI chatbot response wording, conversational tone (formal versus casual), response length, greeting style, call-to-action phrasing, and the presence or absence of suggested reply buttons.
Example: if you suspect your chatbot's welcome message reduces engagement, test a formal version against a casual version while keeping every other element identical. That single-variable constraint is what makes the result meaningful.
Different user populations respond differently to the same response. New users have different context and expectations than returning users. Mobile users on small screens respond differently to long responses than desktop users do. Segmenting by demographics, behavior, device type, or new-versus-returning status surfaces insights that aggregate data obscures — a response that performs poorly overall might be the clear winner for a specific high-value segment.
The control group is not optional. Without it, there is no baseline against which to measure whether a variation represents an actual improvement or just natural fluctuation. Duration matters equally. Tests that run for fewer than seven days are vulnerable to day-of-week effects, seasonal variance, and random noise. A minimum runtime of one week, and ideally two, produces the sample sizes required for statistical significance. Ending a test early because one variant appears to be winning is one of the most common sources of false positives in chatbot optimization.
When evaluating AI chatbot responses in an A/B test, the goal is not to measure activity, it is to measure outcomes. Cekura's testing research recommends combining real-time monitoring with statistical analysis to confirm that observed differences are significant rather than coincidental. Tools like DeepEval, which provides over 14 built-in metrics including hallucination detection and faithfulness checks, make this systematic rather than manual.

Fig 03. Key Metrics
Alphabin's LLM testing research confirms that effective chatbot testing requires validating responses across the actual devices, browsers, operating systems, and network conditions that real users experience. A response that reads clearly on desktop may truncate awkwardly on mobile. A response that loads instantly on fast connections may appear after an off-putting pause on slower networks and that latency alone can tank engagement metrics.
One-time testing before launch is insufficient for chatbots that receive regular updates to prompts, logic, or underlying models. Alphabin's testing framework research recommends integrating A/B testing and automated validation directly into CI/CD (continuous integration/continuous deployment) pipelines so that every code change triggers test suites before reaching production users. Regression testing should replay key AI chatbot response scenarios after every update and compare results against expected outputs — this catches the specific failure mode where a prompt update improves one user segment's experience while silently degrading another's.
Automated testing scales efficiently and catches measurable deviations. Manual testing catches the nuanced user experience failures that metrics do not capture — awkward phrasing that is technically accurate but socially tone-deaf, or a response that provides the correct information in an order that confuses rather than clarifies.
The most effective approach to optimize chatbot responses combines automated metrics (such as BLEU, ROUGE, and BERTScore for language quality) with human evaluation to catch subtle errors that automated tools miss. Neither approach alone is sufficient for AI-powered chatbot optimization.
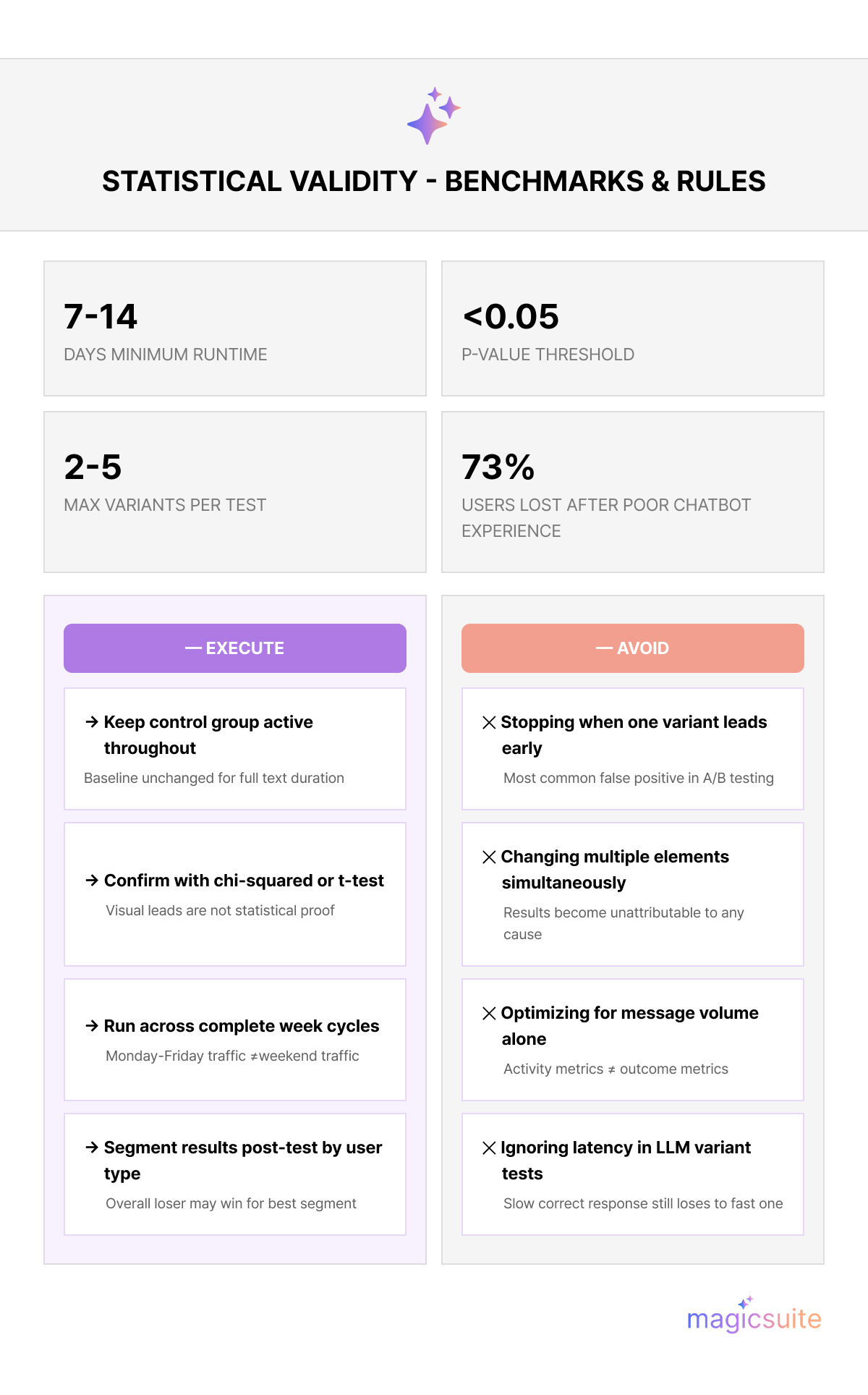
Fig 04. Statistical Validity
A result that looks like a win after three days may reverse itself by day ten. Before implementing a variation as the new default, confirm that the difference between variants meets statistical significance thresholds, typically a p-value below 0.05 and a confidence interval that does not include zero.
Peerdh's A/B testing framework research recommends using methods like chi-squared tests to determine whether observed performance differences are genuine or within the range of normal variation. Declaring winners prematurely based on early data is one of the primary causes of chatbot optimization programs that fail to produce durable improvement.
Implementing a winning AI chatbot response variant is the beginning of the next test cycle. Each test produces not only a winner but also hypotheses about why it won, which directly generates the next test's variables. Chatbot response optimization compounds over time only if teams treat every result as input rather than a final answer.
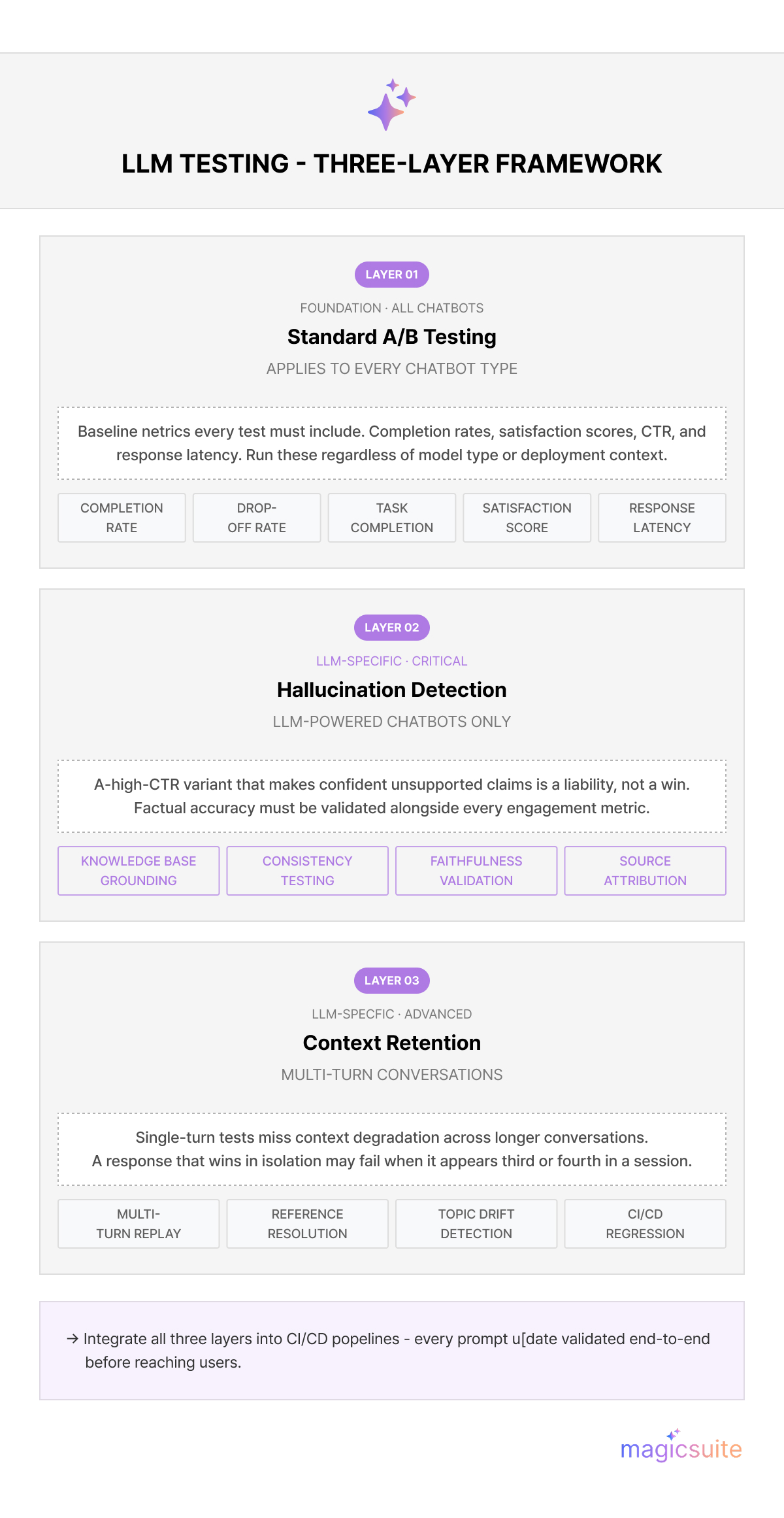
Fig 05. LLM Testing Layers
LLM-powered chatbots introduce two AI chatbot response testing challenges that standard A/B frameworks do not fully address.

Hanna is an industry trend analyst dedicated to tracking the latest advancements and shifts in the market. With a strong background in research and forecasting, she identifies key patterns and emerging opportunities that drive business growth. Hanna’s work helps organizations stay ahead of the curve by providing data-driven insights into evolving industry landscapes.