
RAG 구현은 환각을 1% 미만으로 줄이고 고객 문의 티켓의 40~50%를 자동 처리하여 지원 정확도를 높인다.

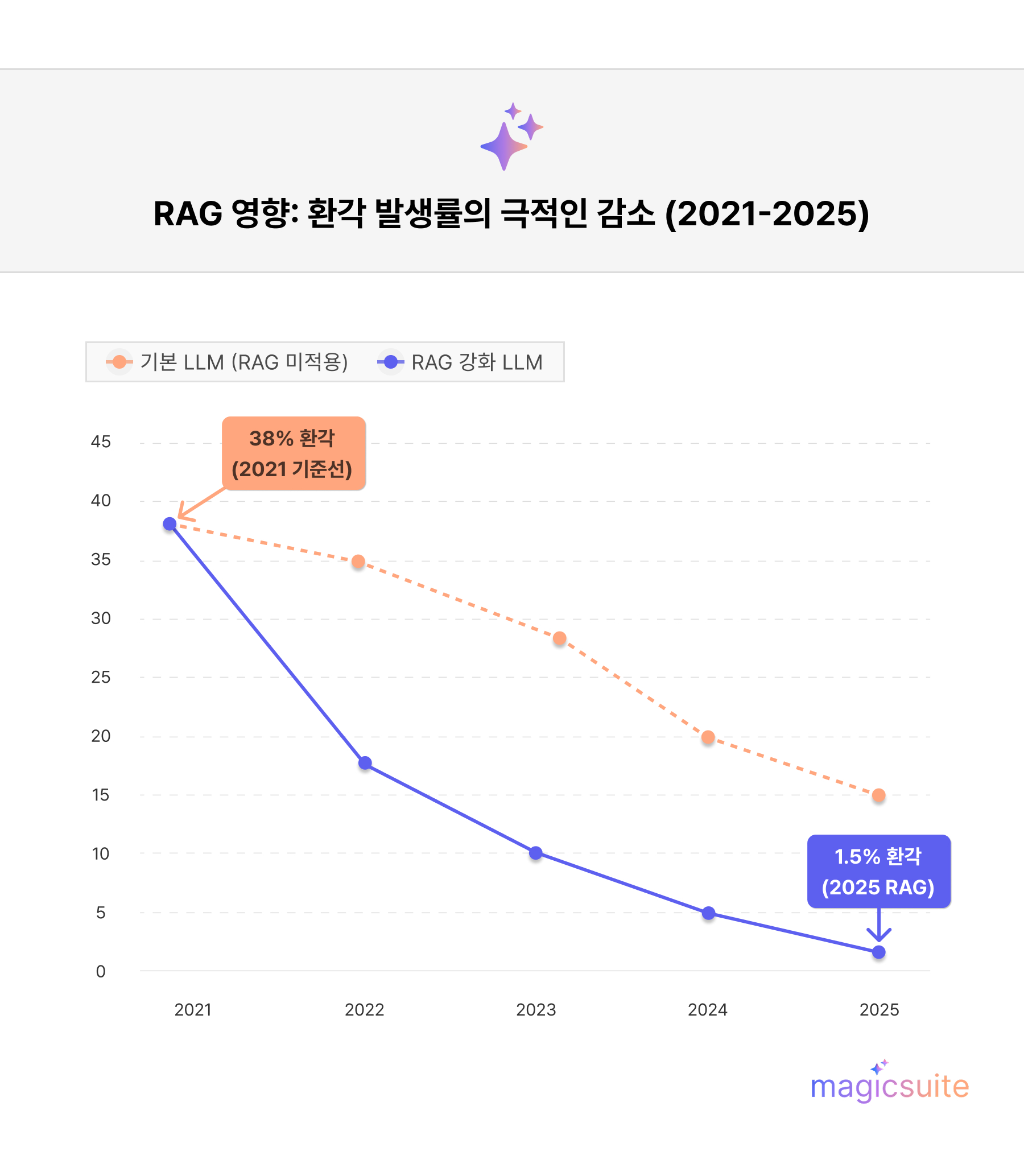
RAG(검색 증강 생성) 구현은 고객 서비스 AI의 핵심 요소로 부상했습니다. 이는 LLM(대규모 언어 모델)의 환각(Hallucination) 현상을 획기적으로 줄여, 2021년 기준 38%에 달했던 기본 모델의 환각률을 2025년 Gemini-2.0과 같은 최신 모델에서 1-3% 미만으로 낮추었습니다. 특히, RAG 강화 시스템은 헬스케어 지원과 같은 특정 도메인 작업에서 거의 0%에 가까운 정확도를 보이며 그 성능을 입증했습니다.
2024년부터 2026년까지의 벤치마크 결과에 따르면, RAG 시스템은 기존 LLM 대비 다음과 같은 괄목할 만한 성과를 보였습니다. 기존 LLM이 의료나 법률과 같은 전문 분야에서 50-82%의 높은 환각률을 보이는 반면, RAG는 고객 문의 티켓의 40-50%를 자동으로 처리하고, 문제 해결 시간을 28-50% 단축시키며, 고객 만족도(CSAT)를 27% 향상시켰습니다.
이는 "지식 드리프트(Knowledge Drift)" 문제를 해결하기에 더욱 중요합니다. 지식 드리프트란, 빠르게 변화하는 지원 문서를 정적인 AI 학습 데이터가 따라가지 못해 오래되거나 잘못된 정보를 생성하는 현상을 의미합니다. RAG는 동적인 검색을 통해 항상 최신 정보에 기반한 답변을 제공함으로써 이 문제를 해결합니다. 따라서 RAG는 단순한 부가 기능이 아니라, 실시간 지식에 근거하여 응답의 정확성과 신뢰성을 보장하는 현대 고객 경험(CX)의 핵심 운영 체제라 할 수 있습니다.
키워드 검색에서 의미 기반의 벡터 검색으로 전환되면서, 임베딩 기술을 통해 문장의 의미를 파악하고 의역된 질문에 대해서도 정확한 정보를 검색할 수 있게 되었습니다. Anthropic의 Contextual Retrieval 기술은 하이브리드 임베딩과 BM25 알고리즘을 결합하여 이를 한 단계 더 발전시켰습니다. 이 기술은 단순히 컨텍스트 창을 채우는 방식을 넘어, 쿼리를 인식하는 컨텍스트 최적화를 통해 검색 실패율을 49-67%까지 줄였습니다.
성공적인 RAG 파이프라인은 다음의 4가지 핵심 기둥으로 구성됩니다.
1. 수집 (Ingestion)- 청킹 및 파싱. 기술 문서, FAQ 등 다양한 문서를 검색 가능한 작은 단위(청크)로 분할하고 벡터로 변환합니다.
2. 임베딩 (Embedding)- 밀집 표현 생성. OpenAI와 같은 모델을 사용하여 텍스트 청크를 의미를 담은 고차원 벡터로 변환합니다.
3. 검색 (Retrieval)- 벡터 검색 및 재순위. Pinecone과 같은 벡터 데이터베이스를 사용하여 사용자 질문과 가장 관련성이 높은 상위 K개의 결과를 신속하게 찾습니다.
4. 생성 (Generation)- LLM 합성. 검색된 컨텍스트를 기반으로 LLM이 환각을 최소화하며 최종 답변을 생성하고 종합합니다.
B2B SaaS 기업인 TechCorp Solutions(500개 이상의 기업 고객 보유)는 RAG 시스템을 도입하여 다음과 같은 성과를 거두었습니다. 월간 2,500건에 달하던 고객 문의 티켓이 875건으로 65% 급감했으며, 평균 응답 시간은 8시간에서 즉시 응답으로 단축되었고, 연간 €45,000의 비용을 절감했습니다.
청구 및 연동과 같은 1차 문의에 대한 자동 처리율은 65%에 달했으며, 최초 접촉 해결률(FCR)은 45%에서 82%로, 고객 만족도(CSAT)는 5점 만점에 3.8점에서 4.8점으로 상승했습니다. 이는 티켓당 비용의 급격한 감소와 첫해 38배의 투자 수익률(ROI) 달성을 의미합니다.
MagicTalk은 이러한 엔터프라이즈급 RAG 스택 전체와 Shopify 또는 Zendesk 데이터와의 실시간 동기화 기능을 중소기업(SMB)에 맞는 합리적인 가격으로 제공하여, 맞춤형 개발 없이도 유사한 수준의 티켓 자동 처리 및 응답 시간 단축 효과를 얻을 수 있도록 지원합니다.

"주문을 환불하고 보증을 확인해 줘"와 같이 여러 단계의 추론이 필요한 복잡한 질문은 단순 검색만으로는 해결할 수 없습니다. 에이전틱 RAG(Agentic RAG)는 자율 에이전트가 여러 도구를 사용하여 계획, 검색, 실행, 검증의 과정을 수행하도록 강화합니다.
에이전틱 RAG는 연구원, 검증자와 같은 전문 에이전트들이 LLM과 RAG를 통해 협력하여 근거에 기반한 결정을 내리는 멀티 에이전트 시스템을 사용합니다. 가트너의 2025-2029년 예측에 따르면, 2026년까지 생성형 AI 가상 비서 도입률이 50%에 이르고, 2029년에는 에이전틱 AI가 일반적인 고객 문제의 80%를 자율적으로 해결할 것으로 전망됩니다.
워크플로우는 다음과 같습니다: 에이전트가 컨텍스트를 검색하고, 데이터베이스 조회와 같은 행동을 추론하며, 출처와 비교하여 사실 여부를 검증한 후, 신뢰도가 높을 때만 답변을 전송합니다.
그라운딩(Grounding) 없는 RAG는 오류를 증폭시킬 위험이 있습니다. RAGAS와 같은 평가 지표는 시스템의 신뢰성을 보장하는 데 필수적입니다. 충실도(Faithfulness)는 답변 내용이 오직 검색된 출처에서만 비롯되었는지를 검증하여 환각을 식별합니다. 관련성(Relevancy)은 답변이 사용자의 질문에 얼마나 직접적으로 부합하는지를 평가하여 주제를 벗어나거나 장황한 결과를 방지합니다. 고객 지원에서 가장 중요한 가치는 정확성이며, RAG는 그 가치를 지키는 금고와 같습니다.
이 로드맵은 RAG 이론을 실제 행동으로 전환하는 4단계 실용 가이드입니다. 각 단계는 실제 사례, 피해야 할 함정, 그리고 빠른 ROI 달성을 위한 팁을 포함합니다.
먼저 제품 설명서, FAQ, 이전 티켓, Slack 대화 등 모든 지식 소스를 전수 감사하여 중복되거나 오래된 정보, 또는 누락된 부분(예: 50페이지 분량의 설명서에 모바일 문제 해결법이 없는 경우)을 파악해야 합니다. 목표는 일반적인 질문의 80%를 커버하는 것입니다.
청킹(Chunking)은 문서를 검색 가능한 조각으로 나누는 과정입니다. 고정된 크기 대신 의미 단위로 분할하는 시맨틱 청킹(512-1024 토큰)을 사용하여 컨텍스트를 보존해야 합니다. 예를 들어, "배터리 교체"에 대한 설명서 섹션을 단계, 경고, 다이어그램을 포함한 하나의 청크로 나눌 수 있습니다. LangChain의 RecursiveCharacterTextSplitter와 같은 도구가 유용하며, 관련 청크를 연결하기 위해 10-20%의 텍스트 중첩을 테스트하는 것이 좋습니다.
•함정: 너무 작은 청크는 컨텍스트를 잃어 20-30%의 검색 실패를 유발할 수 있습니다.
•빠른 성과: 매주 하나의 문서 카테고리를 감사하면 한 달 안에 검색 정확도를 40% 향상시킬 수 있습니다.
필요에 따라 최적의 모델을 선택해야 합니다. 다음은 주요 모델 비교입니다.

다음 단계는 벤치마킹입니다. 100개의 샘플 티켓을 각 모델에 입력하여 환각률(2% 미만 목표)과 응답 시간(3초 미만 목표)을 측정해야 합니다. 공개된 벤치마크는 실제 환경에서의 성능을 15-25% 과장하는 경향이 있으므로, 자체 데이터로 직접 테스트하는 것이 중요합니다.
•예산 팁: 초기에는 품질을 위해 Claude로 시작하고, 대규모 확장을 위해 Llama를 고려할 수 있습니다.
다음 템플릿과 같이 명시적인 프롬프트를 작성하면 환각을 절반으로 줄일 수 있습니다.
"오직 다음 문서들[검색된 청크]만을 사용하여 {query}에 답변하세요. 출처를 명시하세요. 내용이 불분명하면 'X에 대한 추가 정보가 필요합니다'라고 말하세요."
복잡한 질문에는 "먼저 주요 사실을 나열한 다음, 응답하세요"와 같은 연쇄적 사고(Chain-of-Thought) 프롬프트를 추가하고, 2-3개의 과거 티켓을 소수샷 예시(Few-shot examples)로 제공하는 것이 효과적입니다. 50개의 쿼리에 대해 A/B 테스트를 진행하여 관련성을 90%까지 끌어올리세요. 모호한 프롬프트는 추가 토큰을 사용하여 비용을 두 배로 증가시킬 수 있으므로 피해야 합니다.
인간 참여형(Human-in-the-loop) 시스템을 구축해야 합니다. 데이터는 정적이지만 고객의 기대는 동적입니다. 지식 드리프트를 방지하려면 "설정 후 방치"하는 방식에서 벗어나 지속적인 개선 사이클로 전환해야 합니다.
3단계 최적화 사이클:
1.수집 (신호): Zendesk, Slack 등 에이전트의 작업 공간에 간단한 이진 피드백(좋아요/싫어요) 기능을 통합합니다.
2.분석 (감사): AI 생성 응답의 10%만 샘플링하여 실패 패턴(예: 환각된 정책, 오래된 가격)을 식별합니다.
3.개선 (업데이트): 수집된 피드백을 사용하여 임베딩을 미세 조정하거나 인간 피드백 기반 강화 학습(RLHF)을 적용합니다. 이 과정은 사이클당 15-25%의 정확도 향상을 가져올 수 있습니다.
20% 규칙: 주간 피드백 루프를 구현하는 팀은 사이클당 15-25%의 정확도 향상을 경험하며, 이는 AI가 최고참 지원 담당자처럼 사고하도록 효과적으로 훈련시킵니다. 신뢰도가 70% 이상인 응답은 자동으로 승인하여 상담원이 복잡하고 공감이 필요한 문제에 집중하도록 하세요.
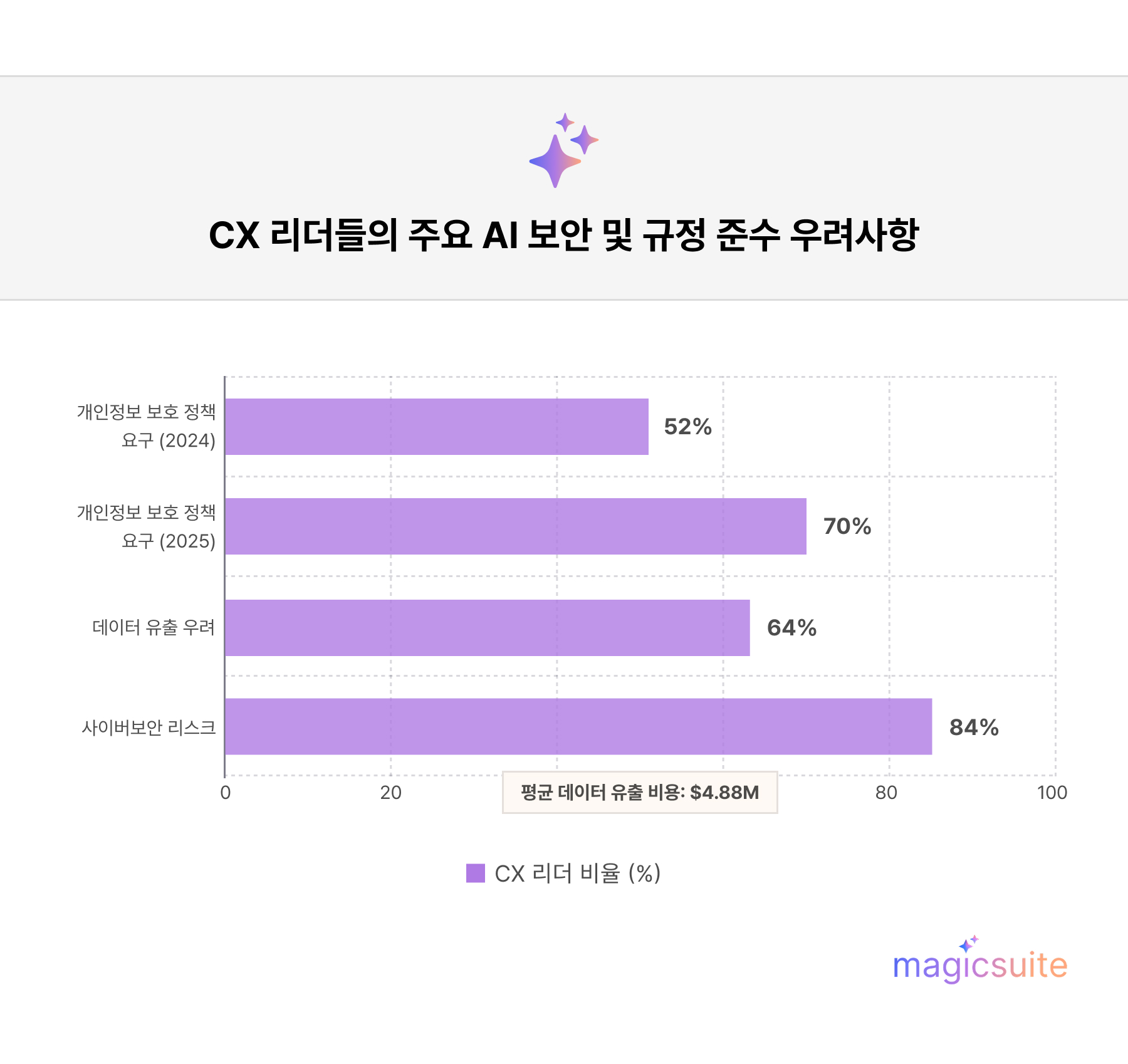
고객 경험 리더들은 신뢰를 훼손하지 않으면서 AI를 배포해야 한다는 압박에 직면해 있습니다. 84%는 사이버 보안을 최고의 AI 우려사항으로 꼽았으며, 64%는 챗봇과 같은 생성형 AI 도구가 고객 개인 식별 정보(PII)에 접근하여 민감한 데이터가 유출될 것을 구체적으로 우려합니다.
최근 설문조사에 따르면, 70%의 기업이 강력한 공급업체 개인정보 보호 정책을 요구하며, 이는 2024년의 52%에서 증가한 수치입니다. 이는 평균 488만 달러의 피해를 초래한 대규모 데이터 유출 사건들에 기인합니다.
다음은 RAG 시스템을 안전하게 보호하기 위한 검증된 보호 조치입니다.
•SOC 2 준수: 제3자 감사를 통해 보안, 가용성, 기밀성에 대한 통제를 검증합니다. CX 임원의 62%가 비준수 공급업체를 거부하므로 이는 엔터프라이즈 계약에 필수적입니다.
•자동 PII 마스킹: Presidio 또는 NVIDIA NeMo와 같은 도구는 입력을 실시간으로 스캔하여 이름, 이메일, 주민등록번호 등을 검색 전에 수정하여 노출을 95%까지 줄입니다.
•데이터 사일로: Pinecone 네임스페이스와 같은 격리된 벡터 저장소에 테넌트 데이터를 분리하여 한 클라이언트의 문서가 다른 클라이언트나 공유 모델로 유출되지 않도록 합니다.
멀티모달 RAG는 음성 쿼리에 거의 인간과 같은 응답을 가능하게 하는 음성 RAG와, 고객이 업로드한 이미지(예: 파손된 부품)를 분석하여 설명서를 검색하는 시각적 RAG와 같은 새로운 트렌드를 이끌고 있습니다. 고객 경험 리더들은 지금 바로 AI 성숙도를 감사하고 에이전틱 RAG를 배포하여 2026년까지 80%의 자율성을 달성하고 효율성을 선도해야 합니다.

Hanna is an industry trend analyst dedicated to tracking the latest advancements and shifts in the market. With a strong background in research and forecasting, she identifies key patterns and emerging opportunities that drive business growth. Hanna’s work helps organizations stay ahead of the curve by providing data-driven insights into evolving industry landscapes.