
AI 챗봇 응답 A/B 테스트로 이탈률을 줄이고 과업 완료율을 높이는 검증된 단계별 실전 방법론을 안내한다.

AI 챗봇 응답 A/B 테스트는 두 가지 이상의 응답 변형을 실증적으로 비교해 어느 쪽이 정의된 목표에 더 잘 부합하는지 측정하는 방법입니다. '어느 쪽이 더 자연스럽게 들리는가'라는 주관적 판단을 측정 가능한 근거로 전환하는 과정이며, AI 챗봇 응답을 대규모로 최적화하는 가장 신뢰할 수 있는 방법론입니다. 이 가이드는 테스트 설계와 사용자 세분화부터 통계적 검증과 지속적인 챗봇 응답 최적화까지 전체 프로세스를 다룹니다.
AI 챗봇 응답 A/B 테스트 — 챗봇 스플릿 테스트라고도 불립니다 — 는 사용자를 AI 챗봇 응답의 서로 다른 버전에 무작위로 배정하고, 어느 버전이 목표 지표를 더 효과적으로 달성하는지 추적하는 방식입니다. 대조군은 원래 응답(버전 A)을 받고, 하나 이상의 실험군은 변형(버전 B, C 등)을 받습니다.
코드가 올바르게 실행되는지를 확인하는 기존 소프트웨어 테스트와 달리, AI 챗봇 응답 A/B 테스트는 응답이 사람에게 실제로 작동하는지를 평가합니다. 기술적으로 완벽한 AI 챗봇 응답도 톤, 길이, 또는 표현 방식이 사용자의 이탈을 유발하면 실패합니다. A/B 테스트는 그 간극을 가정이 아닌 근거로 드러냅니다.
대형 언어 모델(LLM) 기반의 AI 챗봇은 동일한 입력에 대해 세션마다 다른 출력을 생성합니다. 기존 QA는 문법 오류를 잡아내지만, 기술적으로는 정확하지만 대화 맥락상 어색한 응답은 감지하지 못합니다. Cekura의 챗봇 테스트 연구에 따르면, 이러한 예측 불가능성이 LLM 기반 시스템에서 실증적 테스트가 선택이 아닌 필수인 이유이며, A/B 테스트가 기존 QA가 남겨두는 공백을 채우는 이유입니다.
비즈니스적 위험은 명확합니다. ChatBot.com의 연구에 따르면 가상 어시스턴트에서 불쾌한 경험을 한 소비자의 73%는 다시 사용하지 않습니다. 수천 건의 일일 대화에 걸쳐 확산되는 단 하나의 저성과 AI 챗봇 응답 흐름은 그 피해를 빠르게 복합시킵니다. 이것이 응답 수준에서의 대화형 AI 테스트가 비즈니스 필수 사항인 이유입니다.
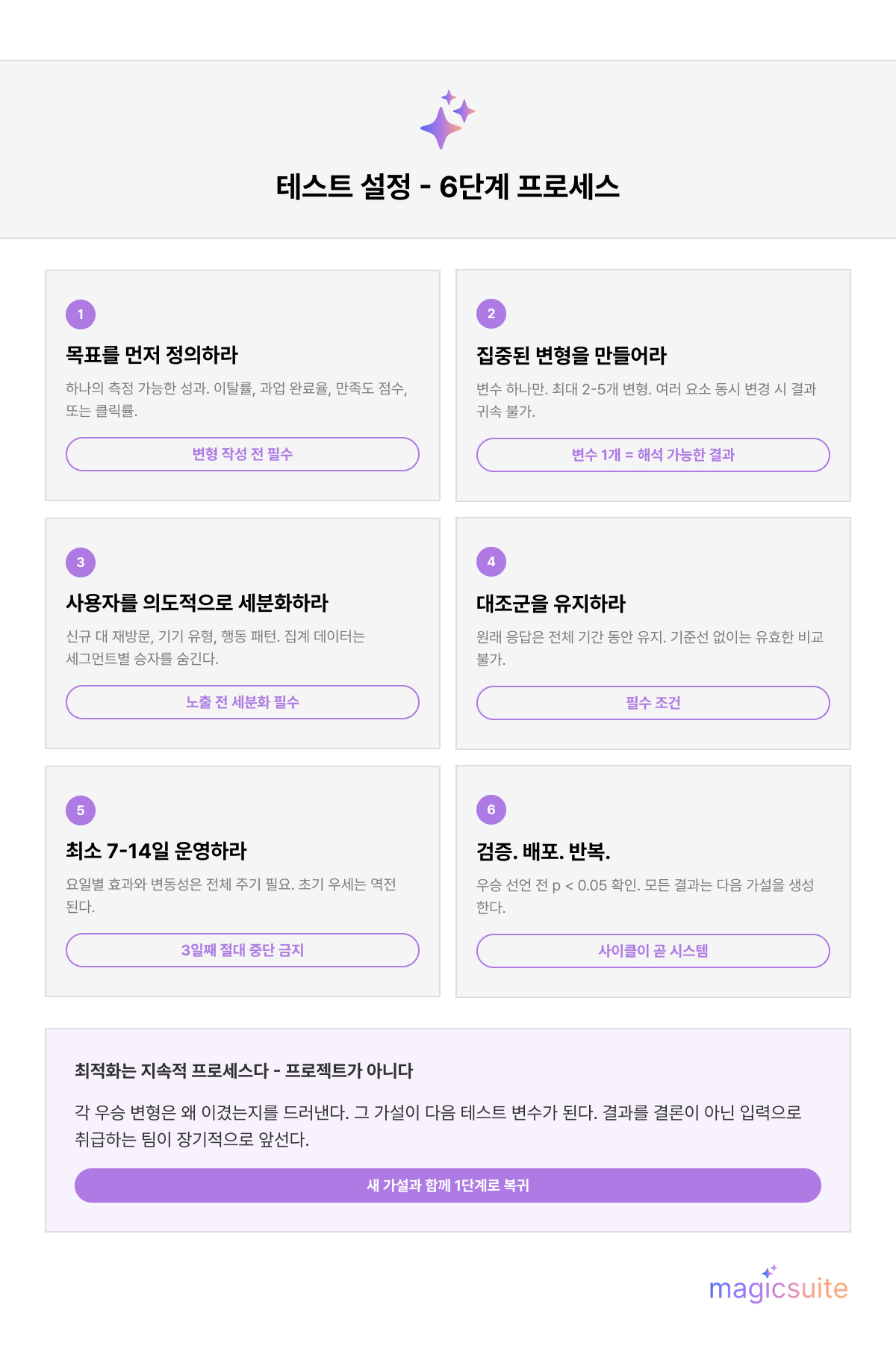
모호한 목표는 해석 불가능한 결과를 낳습니다. 단 하나의 변형도 작성하기 전에, 무엇을 개선하고 싶은지 정확히 정의해야 합니다. 직접적인 비즈니스 임팩트를 가진 목표로는 대화 중간 이탈률 감소, 상담원 에스컬레이션 없이 지원 과업을 완료하는 사용자 비율 증가, 대화 후 만족도 점수 개선, 또는 상품 추천 응답의 클릭률 향상 등이 있습니다.
목표를 사전에 확정하면 데이터를 먼저 수집하고 나중에 의미를 찾으려는 흔한 실수를 방지할 수 있습니다.
한 번에 하나의 변수를 테스트하는 것이 A/B 테스트를 유효하게 만드는 핵심 원칙입니다. 여러 요소를 동시에 변경하면 성과 차이를 특정 원인에 귀속시킬 방법이 없습니다.
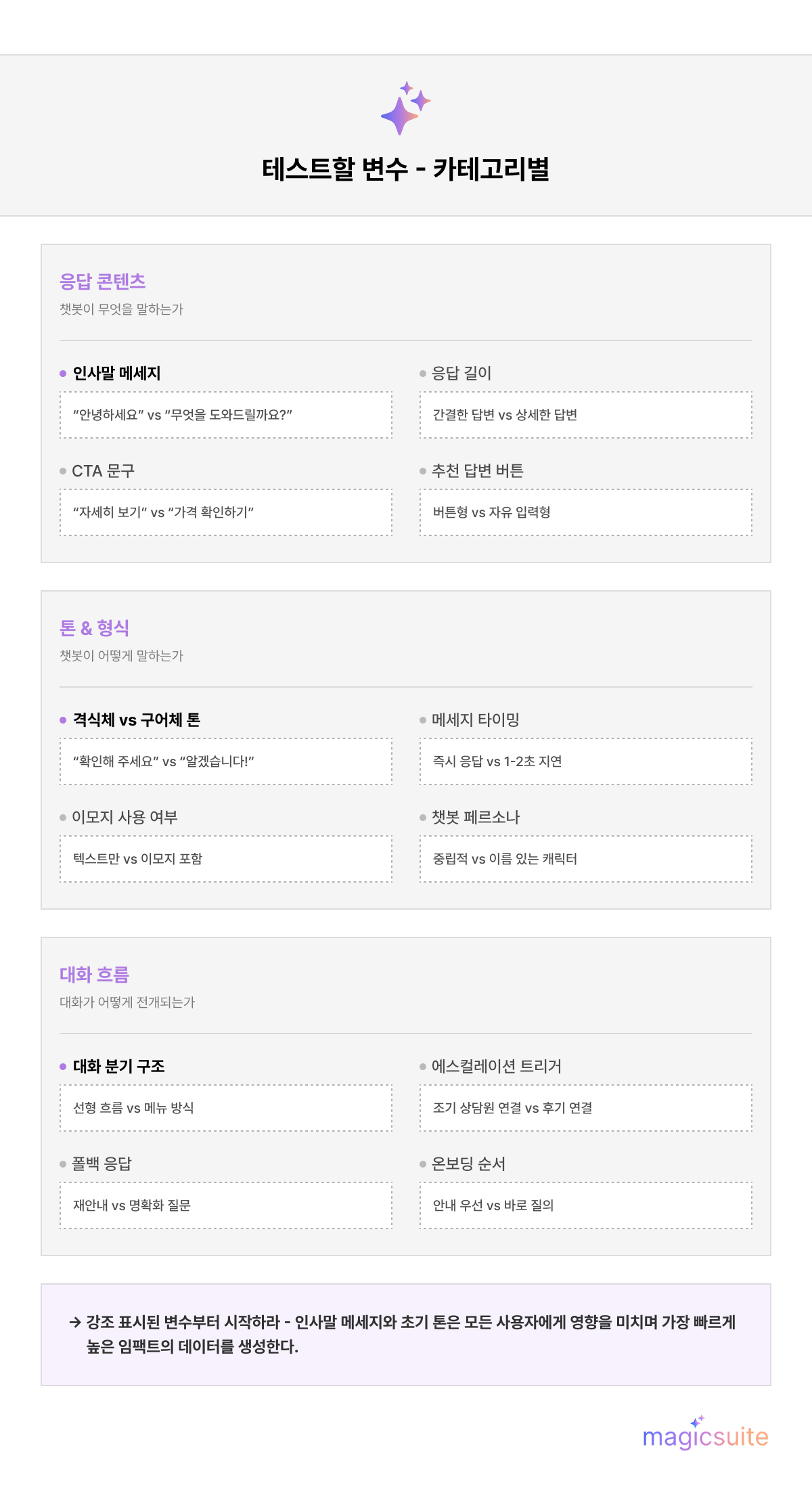
격리할 가치가 있는 변수로는 AI 챗봇 응답 문구, 대화 톤(격식체 대 구어체), 응답 길이, 인사말 스타일, CTA 표현, 추천 답변 버튼의 유무 등이 있습니다. ChatBot의 내장 A/B 테스트 기능은 최대 5개의 서로 다른 흐름을 동시에 지원하여 통제된 조건을 유지하면서 다변량 테스트를 가능하게 합니다.
실용적인 예시: 챗봇의 환영 메시지가 참여도를 낮춘다고 의심된다면, 다른 모든 요소는 동일하게 유지한 채 격식체 버전과 구어체 버전을 비교 테스트하십시오. 그 단일 변수 제약이 결과를 의미 있게 만드는 것입니다.
서로 다른 사용자 집단은 동일한 응답에 다르게 반응합니다. 신규 사용자는 재방문 사용자와 다른 맥락과 기대를 가집니다. 작은 화면의 모바일 사용자는 긴 응답에 데스크탑 사용자와 다르게 반응합니다. 인구통계, 행동, 기기 유형, 또는 신규 대 재방문 여부로 세분화하면 집계 데이터가 가리는 인사이트를 드러낼 수 있습니다.
대조군 — 원래의 수정되지 않은 응답 — 은 선택 사항이 아닙니다. 이것이 없으면 변형이 실질적인 개선인지 자연적 변동인지 측정할 기준이 없습니다.
기간도 마찬가지로 중요합니다. 7일 미만으로 진행된 테스트는 요일별 효과, 계절적 변동, 무작위 노이즈에 취약합니다. 최소 1주, 이상적으로는 2주의 런타임이 통계적 유의성에 필요한 표본 크기를 확보합니다. 하나의 변형이 이기고 있는 것처럼 보인다는 이유로 테스트를 일찍 종료하는 것은 챗봇 최적화에서 가장 흔한 거짓 양성의 원인 중 하나입니다.

AI 챗봇 응답 A/B 테스트에서 지표를 평가할 때, 목표는 활동을 측정하는 것이 아니라 결과를 측정하는 것입니다. Cekura의 테스트 연구는 관찰된 차이가 우연이 아닌 유의미한 것임을 확인하기 위해 실시간 모니터링과 통계적 분석을 결합할 것을 권장합니다. 환각 탐지 및 충실도 검사를 포함해 14개 이상의 내장 지표를 제공하는 DeepEval과 같은 도구는 이 과정을 수동이 아닌 체계적으로 만듭니다.
Alphabin의 LLM 테스트 연구에 따르면, 효과적인 챗봇 테스트는 실제 사용자가 경험하는 실제 기기, 브라우저, 운영체제, 네트워크 조건에서 응답을 검증하는 것을 요구합니다. 데스크탑에서 명확하게 읽히는 응답이 모바일에서는 어색하게 잘릴 수 있습니다. 빠른 연결에서 즉시 로드되는 응답이 느린 네트워크에서는 불쾌한 지연 후 나타날 수 있으며, 그 지연만으로도 참여도 지표가 급락할 수 있습니다.
출시 전 일회성 테스트는 프롬프트, 로직, 또는 기반 모델을 정기적으로 업데이트하는 챗봇에는 불충분합니다. Alphabin의 테스트 프레임워크 연구는 모든 코드 변경이 프로덕션 사용자에게 도달하기 전에 테스트 스위트를 트리거하도록 A/B 테스트와 자동화된 검증을 CI/CD 파이프라인에 직접 통합할 것을 권장합니다. 회귀 테스트는 업데이트 후 주요 AI 챗봇 응답 시나리오를 재현하고 결과를 예상 출력과 비교해야 합니다.
자동화 테스트는 효율적으로 확장되며 측정 가능한 편차를 포착합니다. 수동 테스트는 지표가 포착하지 못하는 미묘한 사용자 경험 실패 — 기술적으로 정확하지만 사회적으로 어색한 표현, 또는 올바른 정보를 혼란을 주는 순서로 제공하는 응답 — 를 잡아냅니다.
Alphabin의 연구에 따르면, 챗봇 응답을 최적화하는 가장 효과적인 접근법은 자동화 지표(언어 품질을 위한 BLEU, ROUGE, BERTScore 등)와 인간 평가를 결합해 자동화 도구가 놓치는 미묘한 오류를 잡아내는 것입니다.
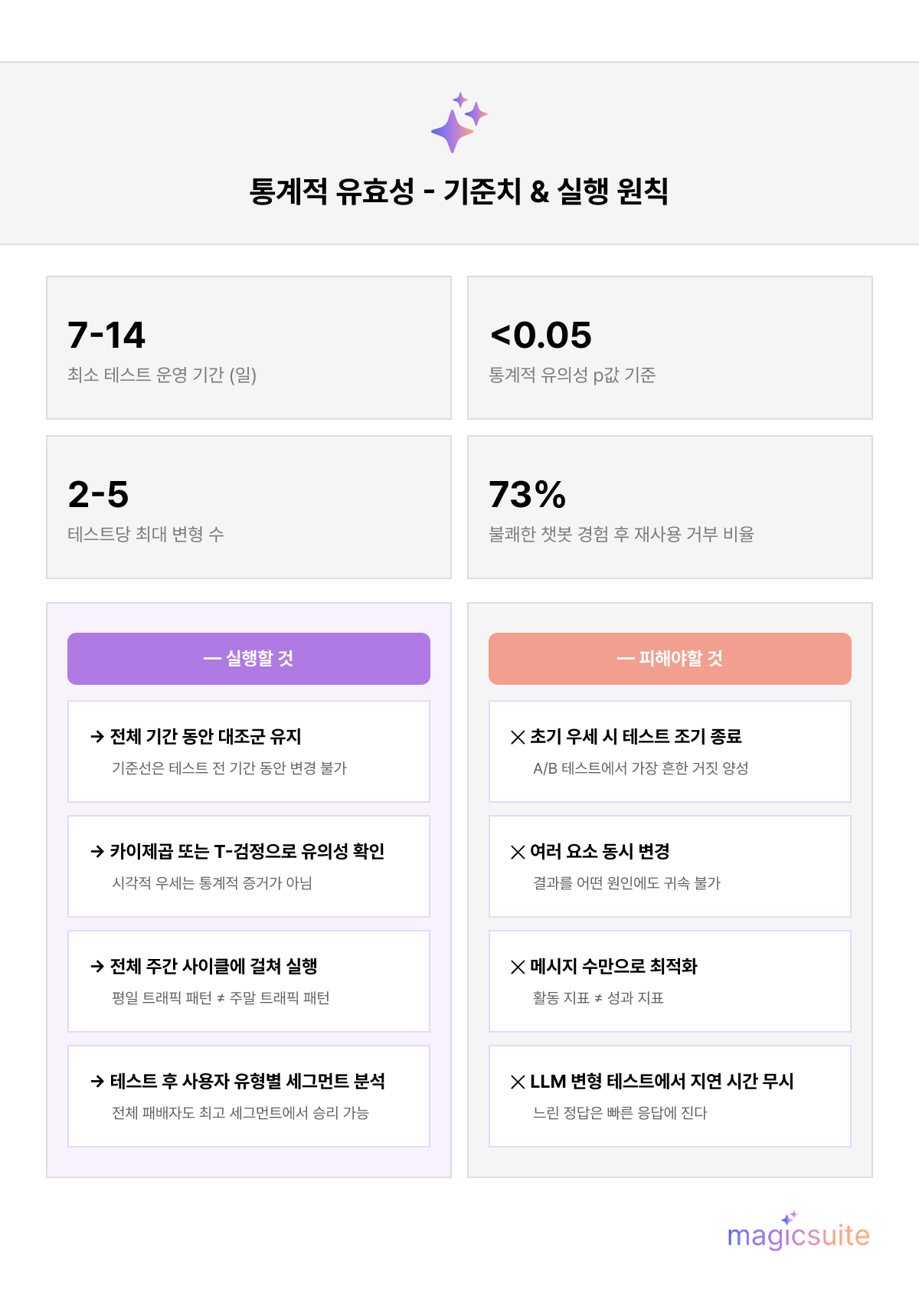
3일 후 우세해 보이는 결과가 10일째에 역전될 수 있습니다. 변형을 새 기본값으로 구현하기 전에, 변형 간의 차이가 통계적 유의성 임계값 — 일반적으로 p값 0.05 미만, 그리고 0을 포함하지 않는 신뢰 구간 — 을 충족하는지 확인하십시오.
Peerdh의 A/B 테스트 프레임워크 연구는 관찰된 성과 차이가 진실인지 정상 변동 범위 내인지를 판단하기 위해 카이제곱 검정과 같은 방법을 사용할 것을 권장합니다.
우승한 AI 챗봇 응답 변형을 구현하는 것은 프로세스의 끝이 아니라 다음 테스트 사이클의 시작입니다. 각 테스트는 우승자뿐만 아니라 왜 이겼는지에 대한 가설도 생성하며, 이것이 다음 테스트의 변수를 직접 호출합니다. 챗봇 응답 최적화는 팀이 모든 결과를 최종 답이 아닌 입력으로 취급할 때만 시간이 지남에 따라 복리 효과를 냅니다.
LLM 기반 챗봇은 표준 A/B 프레임워크가 완전히 다루지 못하는 두 가지 AI 챗봇 응답 테스트 과제를 제기합니다.
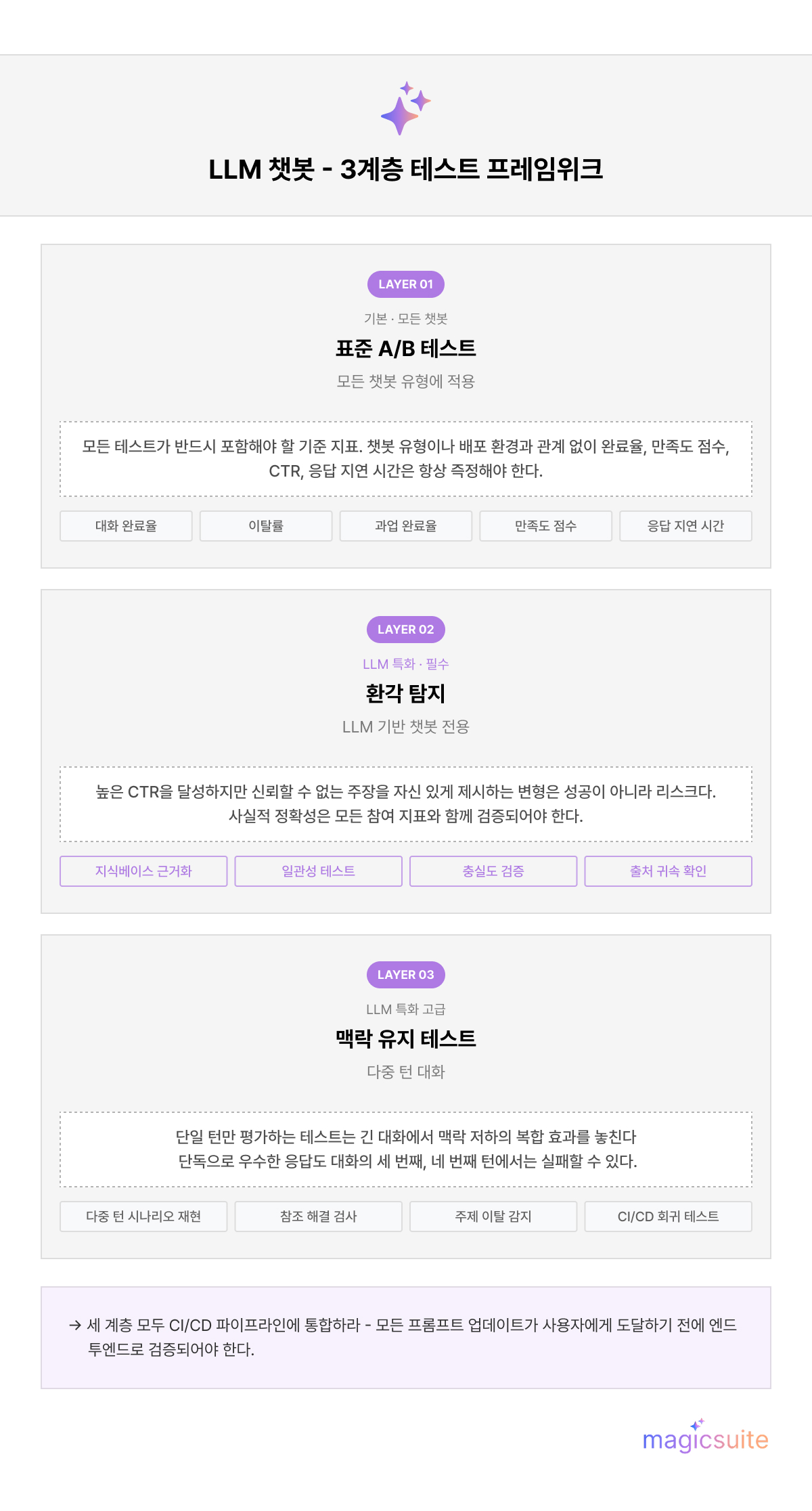
변형 응답의 환각 탐지. AI 챗봇 응답에 대한 A/B 테스트를 실행할 때, 사실적 정확성은 참여도 지표와 함께 검증되어야 합니다. 모델이 신뢰할 수 없는 자신감 있는 주장을 함으로써 더 높은 클릭률을 이끌어내는 변형은 승리가 아니라 리스크입니다. 검증된 지식 베이스에 대해 출력을 근거화하고 일관성 테스트를 사용하는 것 — 챗봇이 다르게 표현된 동등한 질문에 동일한 답변을 제공하는지 확인하는 것 — 이 LLM 특정 A/B 프로그램의 필수 구성 요소입니다.
다중 턴 대화에서의 맥락 유지. 단일 턴 응답만 평가하는 A/B 테스트는 더 긴 대화에서 맥락 저하의 복합 효과를 놓칩니다. Cekura의 연구는 맥락 유지를 별개의 테스트 차원으로 식별합니다. 즉, 모델이 이전 대화 턴을 올바르게 참조하고 교환 전반에 걸쳐 주제 초점을 유지하는지 검증하는 것입니다.

Hanna is an industry trend analyst dedicated to tracking the latest advancements and shifts in the market. With a strong background in research and forecasting, she identifies key patterns and emerging opportunities that drive business growth. Hanna’s work helps organizations stay ahead of the curve by providing data-driven insights into evolving industry landscapes.